






 BTC/HKD+0.03%
BTC/HKD+0.03% ETH/HKD-0.6%
ETH/HKD-0.6% LTC/HKD-0.05%
LTC/HKD-0.05% DOT/HKD+3.2%
DOT/HKD+3.2% ADA/HKD-2.12%
ADA/HKD-2.12% SOL/HKD+1.33%
SOL/HKD+1.33% XRP/HKD-1.32%
XRP/HKD-1.32% DOGE/US+0.46%
DOGE/US+0.46%〇、題記
到底是“左右逢源”還是“舉步維艱”,讓子彈飛一會兒吧。所謂技術壁壘也許就是如何更清晰有效的描述需求了,但也很難形成技術壁壘。至于專利,軟件著作權保護的是制作軟件這個技術本身,而非你使用軟件時的姿勢,所以我想單獨的prompt應該也不會形成專利,但是作為你某個技術的一部分,還是有可能的。LLM現階段的表現是“懂開車的人才能開車”,所以需要更多更懂某個業務,更熟練使用LLM工具的人。這篇文章的目標:討論在當前GPT-4如此強大的技術沖擊下,普通NLP算法工程師該何去何從。本文章主要用來引發思考+討論,如果您是NLP算法工程師,有什么新的觀點或者Comment,可以加微信Alphatue
首先說下結論:GPT-4非常強大,但是我們認為,還沒有到徹底取代NLP算法工程師工作的地步,依然有很多能做的方向。本文分為以下幾部分:
一、GPT-4厲害在哪里?
二、GPT-4存在的問題?
三、NLP工程師可以努力的方向
四、何去何從?
五、申請Prompt專利?我們會不會失業?
一、GPT-4厲害在哪里?
1.更可靠了為什么?詳情可見OpenAI的GPT-4TechnicalReport具體意思是,和以前的GPT-3.5模型相比,GPT-4大大減少了胡說八道的情況。
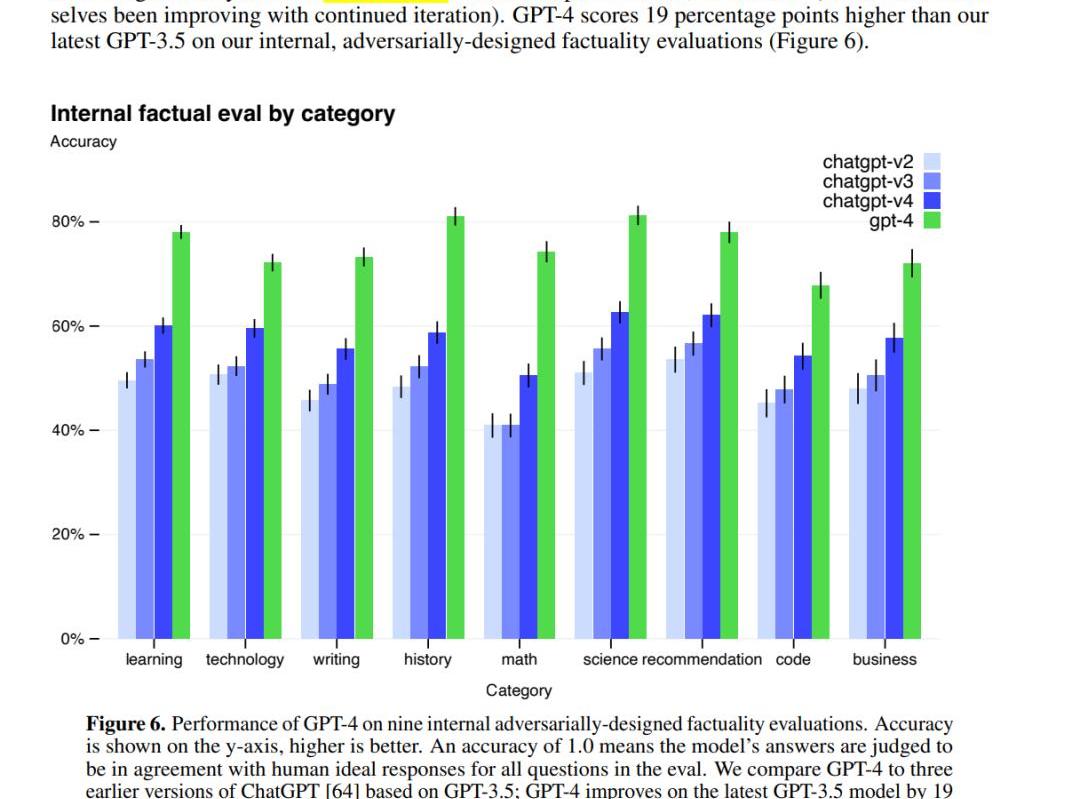
性能更好:比GPT-3.5又提升了一大截
NBA的金州勇士隊和Stephen Curry面臨FTX投資者集體訴訟:金色財經報道,NBA的金州勇士隊和Stephen Curry面臨FTX投資者集體訴訟。該訴訟聲稱金州勇士隊和Curry都參與了一項陰謀,實質上協助或鼓勵了FTX集團的不當行為。[2023/7/26 16:00:45]
具體表現在哪?根據論文里的例子,我們發現GPT-4在技術上有幾個進步:
第一,多模態處理能力:GPT-4可以接受包含文本和圖片的輸入,并生成包括自然語言和代碼在內的文本輸出。這使得它在處理文檔、圖表或屏幕截圖等任務時表現出色。第二,更好的性能和表現:相比前代GPT-3.5,在處理復雜任務時表現更為出色,在各大面向人類的考試中展示出了更高的準確性、可靠性、創造力和理解能力。第三,Test-TimeTechniques擴展能力:GPT-4使用了Test-TimeTechniques如few-shot和chain-of-thoughtprompting進一步擴展了其能力,使其能夠更好地處理新領域和任務。第四,安全性優化:GPT-4重視安全性,生成回復的正確性得到了重點優化。它還進行了對抗性真實性評估,以避免潛在的安全隱患。第五,開源框架支持:OpenAI開源了用于評價大語言模型的開源框架OpenAIEvals,可以幫助研究人員和開發者評估他們的模型,并提供更好的指導。第六,模型訓練和監控:OpenAI強調對模型進行評估和監控的重要性,以避免潛在的安全隱患。GPT-4也已被應用在了OpenAI內部,例如內容生成、銷售和編程,并在模型訓練的第二階段負責輸出評估、對齊工作。這里我們也拋一個問題:(究竟如何定義“模型的性能?”模型越來越難評估了,比如說,市場認為的某些某些不如chatgpt,但是也有人測試覺得更好,是怎么定量的評估呢?)3.Reverseinversescalingprize:一些隨著模型變大性能下降的任務,在GPT-4上不再出現類似現象如何理解reverseinversescalingprize?通過閱讀論文原文,InverseScalingPrize提出的幾個任務,模型性能會隨著scale的擴大而下降,但是我們發現GPT-4扭轉了這一趨勢。也就是說,GPT-4scale擴大,性能也不會下降。見下圖:
Gemini可能在法院裁決后重新上市XRP代幣:金色財經報道,加密貨幣交易所Gemini表示,在美國聯邦法院周四裁定XRP代幣在交易所和通過算法銷售不構成投資合同后,Gemini正在探索Ripple代幣的重新上市。[2023/7/14 10:53:42]
能夠用圖像做prompt:增加圖像信息能進一步提升性能啥是BLIP2?論文:https://arxiv.org/pdf/2301.12597.pdf
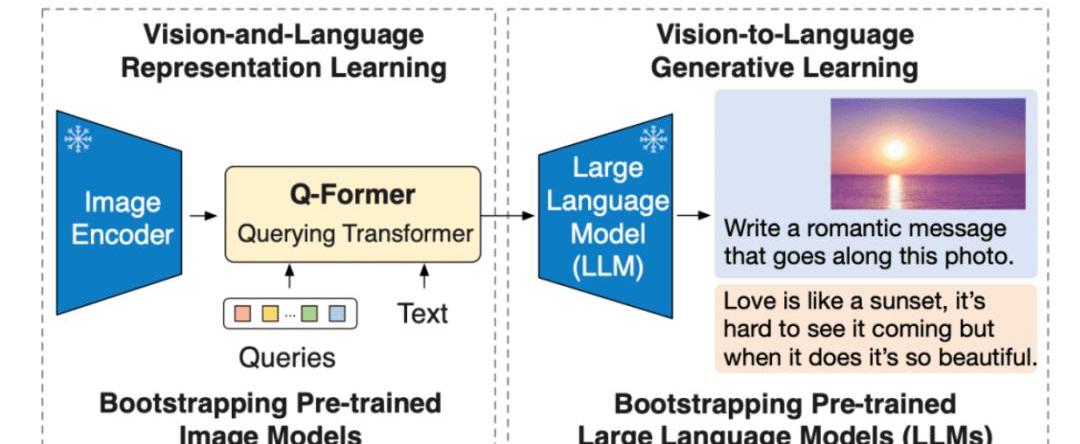
Salesforce研究院的BLIP-2模型,是一種視覺語言模型,可以用于圖像字幕生成、有提示圖像字幕生成、視覺問答及基于聊天的提示等多種應用場景。BLIP-2通過引入一種新的視覺語言預訓練范式來解決端到端視覺語言預訓練的高成本問題,并實現了在多個視覺語言任務上最先進的結果,同時減少了訓練參數量和預訓練成本。
二、GPT-4存在的問題
1.不開源
由于GPT-4完全不公布任何技術細節,所以為什么它有如此強大的能力,我們只能猜,想要研究它變得困難重重。
2.數據安全
ChatGPT的火爆讓大家突然忘了曾經非常看重的數據安全問題,preview版是有可能會參與下次迭代的;而商用API即使強調不會用于模型訓練,敏感業務數據你敢用嗎?
Kaiko:Binance.US上的比特幣溢價是因市場流動性不足,而非做市商退出:金色財經報道,區塊鏈分析公司Kaiko表示,Binance.US上的比特溢價交易是市場流動性不足的表現,而不是做市商退出該平臺,該公司稱,關于做市商可能退出該平臺的猜測只是謠言,因為其市場深度沒有變化,Binance.US的溢價更可能與該交易所在Signature和Silvergate關閉后努力尋找銀行合作伙伴有關,Binance.US的投資者可能希望獲得更快的BTC/USD提款時間,同時急于交易BTC,從而導致交易所出現溢價。(cryptoslate)[2023/5/10 14:55:29]
3.資源消耗大
即使是GPT-3也有175Billion參數,所有的訓練/推理都是極其消耗資源的,從GPT-4的價格上漲了50%來看,我們認為GPT-4的推理消耗資源也上升了約50%左右。
三、NLP工程師可以努力的方向
這也是最近討論比較熱烈的一個問題。在我們探討這個問題之前,可以先思考一下理想的NLP模型應該具有哪些特征。我們認為,比較理想的模型是:
安全可靠/支持長文本/小/快/私有化部署。
所以從個人觀點出發,給出一些我們比較關注的方向,拋磚引玉:
1.hallucination
目前LLM最大的問題就是hallucination(hallucination舉個例子,就是ChatGPT會一本正經的胡說八道)。那么目前主流兩種思路:alignment/多模態。①alignment:alignment就是讓模型理解人類語言
數字資產公司 Taurus 完成 6500 萬美元 B 輪融資:金色財經報道,數字資產公司 Taurus 完成 6500 萬美元 B 輪融資,Credit Suisse 領投,Arab Bank Switzerland、Investis 參投。
據悉,Taurus 是一家總部位于瑞士的數字資產基礎設施公司,專注于為歐洲的金融機構提供托管和代幣化等數字資產服務。該公司于 2020 年 4 月完成 1100 萬美元 A 輪融資。Taurus 表示未來幾個月內將在巴黎和迪拜開設辦事處,然后在東南亞和美洲展開業務。為此,Taurus 計劃今年將員工人數從 60 人增加到 100 人左右。(The Block)[2023/2/14 12:05:50]
②多模態:多模態是指涉及多個感官或媒體形式的信息處理和表達方式。在自然語言處理和計算機視覺等領域,多模態通常是指同時處理和理解多種輸入方式,如文本、音頻和圖像等。多模態信息處理可以幫助計算機更好地理解復雜的人類交互和情境,從而提高計算機的智能化水平和應用效果。例如,在圖像字幕生成任務中,計算機需要同時處理圖像和文本,根據圖像內容生成相關的文字描述。
Alignment至于如何做alignment,學術界主要是instruction-tuning為主,OpenAI的路線是RLHF,然而普通玩家我是完全不推薦做RL的,只要仔細閱讀InstructGPT/GPT-4paper中關于rewardmodel部分就能勸退了。所以對于我們普通玩家,是否有別的路徑?多模態GPT4的Paper上看,效果是不錯的,不過我們目前還在實踐,歡迎實踐過的同仁來討論。2.復現GPT-4/ChatGPT/GPT-3.5/InstructGPT
2022年服貿會新設環境服務專題增加元宇宙元素:8月6日消息,2022年中國國際服務貿易交易會將于8月31日至9月5日在國家會議中心和首鋼園區舉辦,今年主題為“服務合作促發展 綠色創新迎未來”。本屆服貿會新設環境服務專題,將重點展示生態環保、綠色節能新技術、新應用,助力實現“雙碳”目標;還突出數字科技新元素,增加元宇宙元素,展示元宇宙、新一代互聯網等技術和應用,采用元宇宙技術打造成果發布廳,促進元宇宙從概念走向應用。[2022/8/6 12:06:44]
不開源只能復現,目前主要有(https://github.com/facebookresearch/llama)/(https://huggingface.co/bigscience/bloom)此外還有不開源但是可以使用API訪問的百度文心一言/ChatGLM等。
3.如何評估LLM
很多人提到百度文心一言性能“不夠好”,具體指的是哪里不夠好?想要回答這個問題,就涉及到:究竟如何量化評估LLM的性能?曾經自動化的方案及Benchmark的參考意義,隨著LLM的能力提升顯得越來越弱,現在急需新的數據集/評估方案。目前的工作有:(https://github.com/openai/evals)(https://github.com/stanford-crfm/helm)
4.支持長文本
更長的輸入,對某些任務是有利的,那么如何讓模型支持更長的輸入?
主要的思路有兩個:
訓練時使用較短文本,推理時外推更長的位置信息,使模型獲得處理長文本的能力,如bloom中使用的(https://arxiv.org/pdf/2108.12409.pdf)調整模型結構,如最近的工作:(https://arxiv.org/pdf/2303.09752.pdf)PS:GPT-4的輸入從GPT-3.5的4K(or8K?)提升到了30K,具體是如何做的呢?
5.變小變快
相同架構的模型通常變小就會變快,讓模型變小的方法主要是蒸餾/量化/train小模型,這個方向目前工作有:(https://github.com/tatsu-lab/stanford_alpaca)(https://github.com/TimDettmers/bitsandbytes),中文上也有(https://github.com/THUDM/ChatGLM-6B)/(https://github.com/LianjiaTech/BELLE)等
6.低成本inference
如何在低成本設備上使用這些模型?如單張GPU上跑大模型或普通CPU上跑模型。這個方向的工作也有(https://github.com/FMInference/FlexGen)/(https://github.com/ggerganov/llama.cpp)等。
7.低成本優化
低成本fine-tuning主要有兩個方向:①parameter-efficient②sample-efficient.parameter-efficient?的思路目前主要有prompt-tuning/prefix-tuning/LoRA/Adapter等參考(https://github.com/huggingface/peft)
sample-efficient可以幫助我們如何更有效的構造訓練集最近的工作有(http://arxiv.org/abs/2303.08114)
8.優化器
優化器決定了我們訓練時需要的資源。雖然我們通常使用Adam優化器,但是其需要2倍額外顯存,而google好像用Adafactor更多一點,最近他們又出了一個新工作
(https://arxiv.org/abs/2302.06675).9.更可控
如從可控生成角度看,目前可控主要通過controltoken來實現,有沒有更好的辦法來實現更“精細”的控制?正如controlnet之于stablediffusion。
10.識別AIGC
如何判別內容是人寫的還是模型生成的呢?隨著模型的性能越來越強,識別AIGC也越來越困難。目前的工作也有watermark/(https://gptzero.me/)等不過我感覺還沒什么特別有效的方案目前。對此我有個簡單的思路:將AI生成的與非AI生成的看作是兩種不同的語言,如code與英語一樣,雖然都是相同符號構成,但是對應不同語言。使用大量的AI生成的內容pretrain一個”AI語言模型“,再來進行識別。
11.單一任務/領域刷榜
我認為在某個任務/領域上通過小模型挑戰大模型依然有意義,LLM雖然強大,但是依然有太多我們不知道的能力,通過小模型刷榜也許能提供一些思路,就像PET本意是挑戰GPT-3,卻打開了LLM的新思路。
四、何去何從
1.普通工程師
這種新的革命性的技術我們普通工程師通常都不是第一線的,我們第一次真正使用bert也是在其出來兩年后了。即使今天,也有很多場景/公司不使用bert這個技術。換個角度,即使我們想參與,我想能參與訓練/fine-tuning一個10B規模模型的工程師都相當少,更別提更大的了。所以到底是“左右逢源”還是“舉步維艱”,讓子彈飛一會兒吧。
2.普通用戶
生活中不缺少美,而是缺少發現美的眼睛。對于普通用戶來說,要努力提高自己的鑒別能力
五、番外
1.通過Prompt構建技術壁壘/申請prompt專利
隨著alignment的進一步優化,LLM通常越來越理解自然語言,所以我們認為prompt-trick越來越不重要,而清晰地用prompt描述你的需求越來越重要。所謂技術壁壘也許就是如何更清晰有效的描述需求了,但也很難形成技術壁壘。至于專利,軟件著作權保護的是制作軟件這個技術本身,而非你使用軟件時的姿勢,所以我想單獨的prompt應該也不會形成專利,但是作為你某個技術的一部分,還是有可能的。
2.會不會失業
我們認為不會失業,但會轉變一部分人的工作方式。在計算這件事上,人類早已被計算機遠遠地甩在后面,而計算機的出現也帶來了大量的新工作。尤其是LLM現階段的表現是“懂開車的人才能開車”,所以需要更多更懂某個業務,更熟練使用LLM工具的人。
ve(3,3)類項目在最近的反彈行情中取得了更好的成績,Optimism上的Velodrome、BNB鏈上的Thena、Arbitrum上的Solidlizard、以太坊上的Solidlyv2、.
1900/1/1 0:00:003月22日,NFT游戲Aavegotchi宣布正利用PolygonSupernets推出自己的區塊鏈Gotchichain.
1900/1/1 0:00:00a16z合伙人ChrisDixon曾解釋道,Web1是「讀」,Web2是「讀和寫」,Web3是「讀、寫和擁有」。本篇通過對Web3的解釋,試圖讓我們理解為什么公共產品在Web3中的構建很重要.
1900/1/1 0:00:00摘要:據愛范兒報道,昨晚,英偉達、微軟、Google、Adobe等廠商在相差無幾的時間里都推出了各自的AI服務,你追我趕之勢仿佛在傳達著同一個焦慮:「在這個大AI時代,如果不想被人顛覆.
1900/1/1 0:00:00原文作者|Korpi 原文編譯|白澤研究院 Arbitrum最近火了!憑借著價值>10億美元的$ARB空投,大量資金將涌入其生態系統項目,使得流動性“水漲船高”.
1900/1/1 0:00:00昨天,Binance新一期IEO項目SpaceID正是開放交易,較IEO價格上漲超過2000%?,再次激起市場對新項目的參與熱情.
1900/1/1 0:00:00


