






 BTC/HKD+1.86%
BTC/HKD+1.86% ETH/HKD+2.41%
ETH/HKD+2.41% LTC/HKD+3.26%
LTC/HKD+3.26% DOT/HKD+3.7%
DOT/HKD+3.7% ADA/HKD-0.99%
ADA/HKD-0.99% SOL/HKD+2.23%
SOL/HKD+2.23% XRP/HKD-0.53%
XRP/HKD-0.53% DOGE/US+1.86%
DOGE/US+1.86%原文來源:Bryan,IOSGVentures
本文將主要討論ZKP作為擴容方案的發展現狀,從理論層面描述產生證明過程中主要需要優化的幾個維度,并引深到不同擴容方案對于加速的需求。然后再圍繞硬件方案著重展開,展望zk硬件加速領域的摩爾定律。最后,關于硬件zk加速領域的一些機會和現狀,會在文末闡述。首先,影響證明速度的主要有三個維度:證明系統,待證明電路規模,和算法軟硬件優化。
對于證明系統來說,凡是使用橢圓曲線的算法,也就是市面上主流的Groth16,目前都有時間長的瓶頸。對于FRI-based算法,如ZK-Stark,其多項式承諾產生方式是HashFunction,不牽扯EC,所以并不涉及MSM運算。
證明系統是基礎,待證明電路的規模也是核心的硬件優化的需求之一。近期討論很火的ZKEVM據對以太坊的兼容程度不同,導致了電路的復雜程度的不同,比如Zksync/Starkware構建了與原生以太坊不同的虛擬機,從而繞開了一些以太坊原生的不適合利用zk處理的底層代碼,縮小了電路的復雜長度,而Scroll/Hermez這樣目標從最底端兼容的zkevm的電路自然也會更復雜。
一個方便理解的比方是,電路的復雜性可以理解為一輛巴士上的座位,比如普通日子下需要搭載的乘客數在30人以下,有些巴士選擇了30人的座位,這些巴士就是Zksync/StarkWare,而一年中也有一些日子有特別多的乘客,一般的巴士坐不下,所以有一些巴士設計的座位更多。但是這些日子可能比較少,會導致平時會有很多空余的座位。
硬件加速對于這些電路設計更復雜的電路更迫切,不過這更多是一個Specturm的事情,對于ZKEVM也同樣有利無弊。
不同證明系統優化的需求/側重點:
基本:
當一個待證明事物經過電路處理之后,會得到一組標量和向量,之后被用來產生多項式或者其他形式的代數形式如innerproductargument(groth16)。這個多項式依然很冗長,如果直接生成證明那么無論是證明大小或是驗證時常都很大。所以我們需要將這個多項式進一步簡化。這里的優化方式叫做多項式承諾,可以理解為多項式的一種特殊的哈希值。以代數為基礎的多項式承諾有KZG,IPA,DARK,這些都是利用橢圓曲線產生承諾。
Compound Labs推出Encumber機制,可分離代幣所有權與轉讓權:7月7日消息,Compound Labs推出Encumber機制,這是一種讓用戶將代幣所有權與轉讓權分離的機制。當代幣所有者將其代幣抵押到另一個賬戶時,允許其授予該賬戶在保留所有權的同時轉讓代幣的專有權利。這使得代幣持有者能夠承諾智能合約中的條款,而無需將其代幣所有權轉移到外部地址。通過使用 Encumber,代幣持有者可以保留空投、治理權或對內容與活動的訪問權,同時仍然參與DeFi。[2023/7/7 22:24:09]
FRI是以HashFunction為產生承諾的主要途徑。多項式承諾的選擇主要是圍繞幾點-安全性,Performance。安全性在這里主要是考慮到在setup階段。如果產生secret所使用的randomness是公開的,比如FRI,那么我們就說這個setup是透明的。如果產生secret所利用的randomness是私密的,需要Prover在使用之后就銷毀,那么這個setup是需要被信任的。MPC是一種解決這里需要信任的手段,但是實際應用中發現這個是需要用戶來承擔一定的成本。
而上述提到的在安全性方面相對卓越的FRI在Performance并不理想,同時,雖然Pairing-friendly橢圓曲線的Performance比較卓越,但是當考慮將recursion加入時,因適合的曲線并不多,所以也是相當大的存在相當大的overhead。
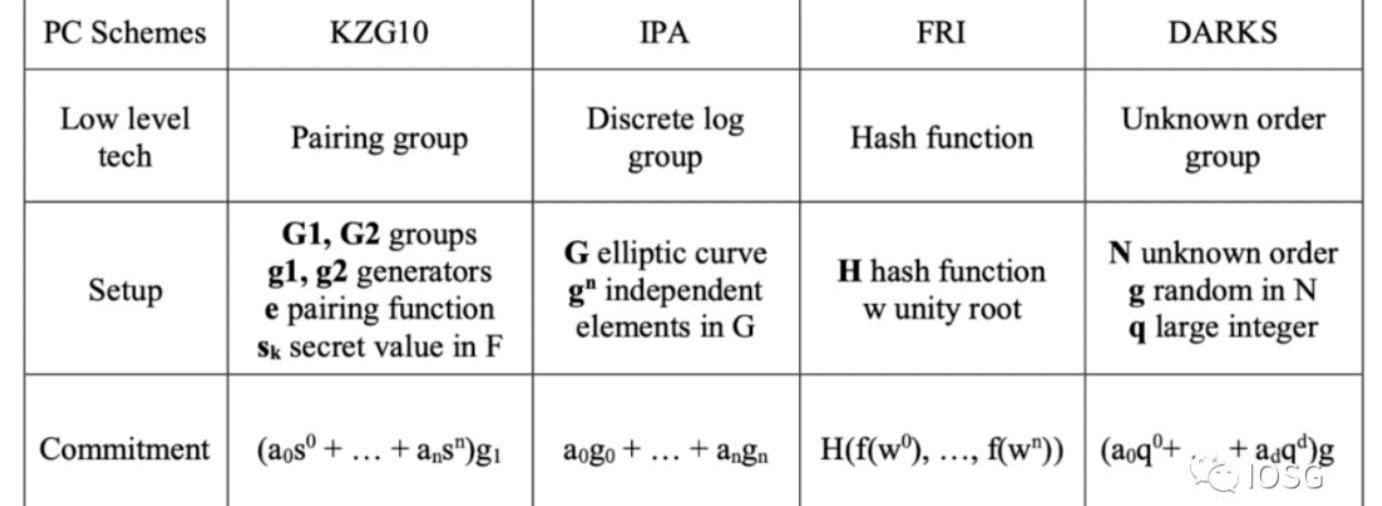

行業現狀:
當前不管是的基于Plonk(matterlabs)或者基于Ultra-Plonk(Scroll,PSE),他們最后的多項式commitment都是基于KZG,故而Prover的大部分工作都會涉及到大量的FFT計算(產生多項式)和ECC點乘MSM運算。
數據:持有超過1萬枚以上ETH的地址數量達到1個月低點:金色財經報道,據glassnode數據,持有超過1萬枚以上ETH的地址數量剛剛達到1,162個的1個月低點。[2022/10/24 16:36:23]
在純plonk模式下,由于需要commit的point數量不大,MSM運算所占的Prove時間比重不高,所以優化FFT性能能夠短期帶來更大的性能提升。但是在UltraPlonk框架下,由于引入了customergate,prover階段設計的commit的point數量變多,使得MSM運算的性能優化也變得非常重要。(目前MSM運算進行pippenger優化之后,依然需要log(P(logB))(B是exp的上界,p是參與MSM的point的數量)。
目前新一代Plonky2證明系統由于所采用的多項式commitment不再是KZG而是STARK系統中常見的FRI,使得Plonky2的prover不需要再考慮MSM,從而理論上該系統的性能提升不再依賴MSM相關的算法優化。plonky2的作者Mir(目前的PolygonZero)正在大力推廣該系統。不過由于plonky2采用的數域GoldilocksField對于編寫elliptic相關的hash算法相關的電路不是特別友好,所以盡管GoldilocksField在機器word運算方面優勢明顯,但是依然難以判斷Mir和PSE/Scroll方案誰是更好的方案。
基于對Plonk,Ultraplonk,Plonky2的Prove算法的綜合考量,需要硬件加速的模塊大概率還是會集中在FFT,MSM,HASH三個方向。
Prover的另一個瓶頸是witness的生成,通常普通非zk計算會略去大量的中間變量,但是在ZKprove的過程中,所有witness都需要被記錄,并且會參與之后的FFT計算,所以如何高效的并行witness計算也會是prover礦機需要潛在考慮的方向。
今天是比特幣誕生第5000天:9月13日消息,今天是比特幣誕生第5000天,比特幣(Bitcoin)的概念最初由中本聰在2008年11月1日提出。2009年1月3日,中本聰發布了開源的第一版比特幣客戶端,宣告了比特幣的誕生,同時還通過挖礦得到了50枚比特幣,產生了創始區塊(Genesisblock),中本聰在創世區塊里留下了當天《泰晤士報》頭條:2009年1月3日,財政大臣正處于實施第二輪銀行緊急援助的邊緣。[2022/9/13 13:26:59]
加速ZKP方面的嘗試:recursiveproof-StarkNet的fractalL3概念基于recursiveproof的概念,Zksync的fractalhyperscaling,Scroll也有類似的優化。
>RecursivezkSNARK概念是對一個ProofA的驗證過程進行證明,從而產生另一個ProofB。只要Verifier能接受B,那么相當于也接受了A。遞歸SNARK可以也可以把多個證明聚合在一起,比如把A1A2A3A4的驗證過程聚合為B;遞歸SNARK也可以把一段很長的計算過程拆解為若干步,每一步的計算證明S1都要在下一步的計算證明中得到驗證,即計算一步,驗證一步,再計算下一步,這樣會讓Verifier只需要驗證最后一步即可,并避免構造一個不定長的大電路的難度。
理論上zkSNARK都支持遞歸,有些zkSNARK方案可以直接將Verifier用電路實現,另一些zkSNARK需要把Verifier算法拆分成易于電路化的部分和不易電路化的部分,后者采用滯后聚合驗證的策略,把驗證過程放到最后一步的驗證過程中。
在L2的未來應用上,遞歸的優勢可以通過對于帶證明事物的歸納而進一步將成本與性能等要求進一步降低。
第一種情況(application-agnostic)是針對不同的待證明的事物,比如一個是stateupdate另一個是MerkleTree,這兩個待證明事物的proof可以合并成一個proof但是依舊存在兩個輸出結果(用來分別驗證的publickey)
數據:69995703枚USDT從未知錢包轉移到Kraken:金色財經報道,WhaleAlert數據顯示,69,995,703枚USDT從未知錢包轉移到Kraken。[2022/8/27 12:51:23]
第二種情況(applicativerecursion)是針對同類的待證明的事物,比如兩個都是stateupdate,那么這兩個事物可以在生成proof前進行聚合,且僅有一個輸出結果,該結果就是經歷了兩次update的statedifference。
除了recursiveproof以及下文主要討論的硬件加速之外,還有其他的加速ZKP的方式,比如customgates,移除FFT等,但本文因篇幅原因不予討論。
硬件加速
硬件加速在密碼學中一直是一種普遍的加速密碼學證明的方式,無論是對于RSA,還是早期對于zcash/filecoin的zk-snark的GPU-based的優化方式。
硬件選擇
在以太坊TheMerge發生之后,不可避免將會有大量的GPU算力冗余,下圖是英偉達GPU旗艦產品RTX3090的成交價格,也顯示買方勢力較為薄弱。
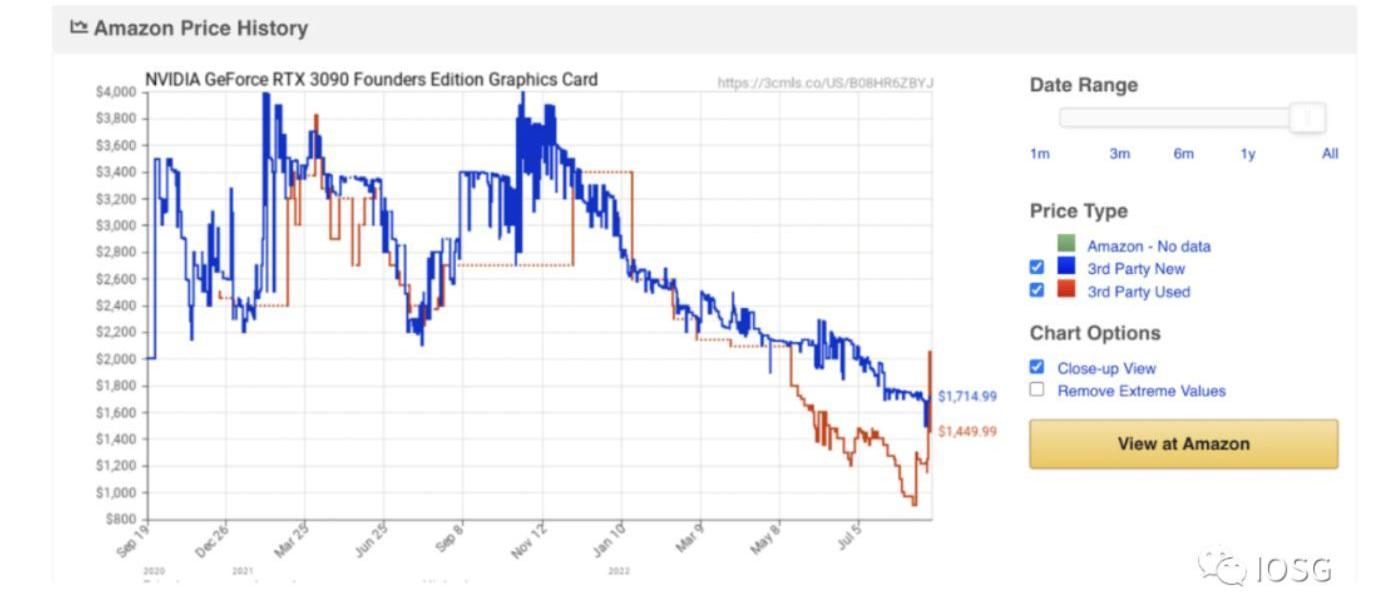
在GPU價格處于低點,同時大量GPU算力閑置,一個自然的問題就是,是否GPU是合適的加速zk的硬件呢?硬件端主要有三個選擇,GPU/FPGA/ASIC。
FPGAvsGPU:?
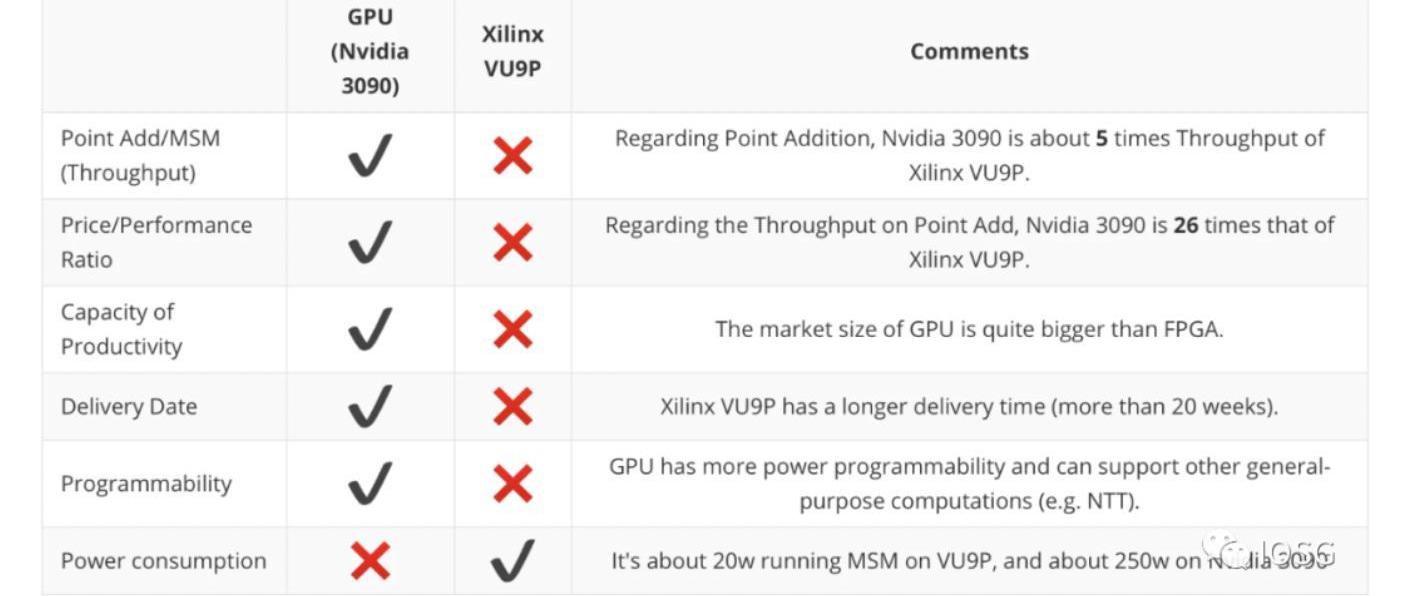
先看總結:以下是trapdoor-tech關于GPU以及FPGA在幾個維度的總結,非常重要的一點是:GPU在性能方面要高于FPGA,而FPGA在能源消耗則更具有優勢。
巴西央行行長:將允許該國私人銀行發行自己的穩定幣:金色財經報道,據巴西中央銀行行長 Roberto Campos Neto 的聲明,巴西中央銀行數字貨幣(CBDC),將更像是一種批發資產,而不是一種以零售為重點的公共代幣。Campos Neto 表示,將允許該國私人銀行在自己存款的基礎上發行自己的穩定幣,并將為此開發一項技術,他們將不得不投資,因為他們可以從中獲得收益。而一旦他們開發出這種技術,在存款上發行穩定幣的協議將基本上與其他各種數字資產的貨幣化相同。
此外,Campos Neto解釋說,數字實物將有一個非常獨特的重點,目標是在不損害私人銀行信貸功能的情況下將資產貨幣化,并將其用作抵押品。(bitcoin.com)[2022/6/9 4:13:15]
?一個更直觀的來自于Ingoyama的具體的運行結果:??
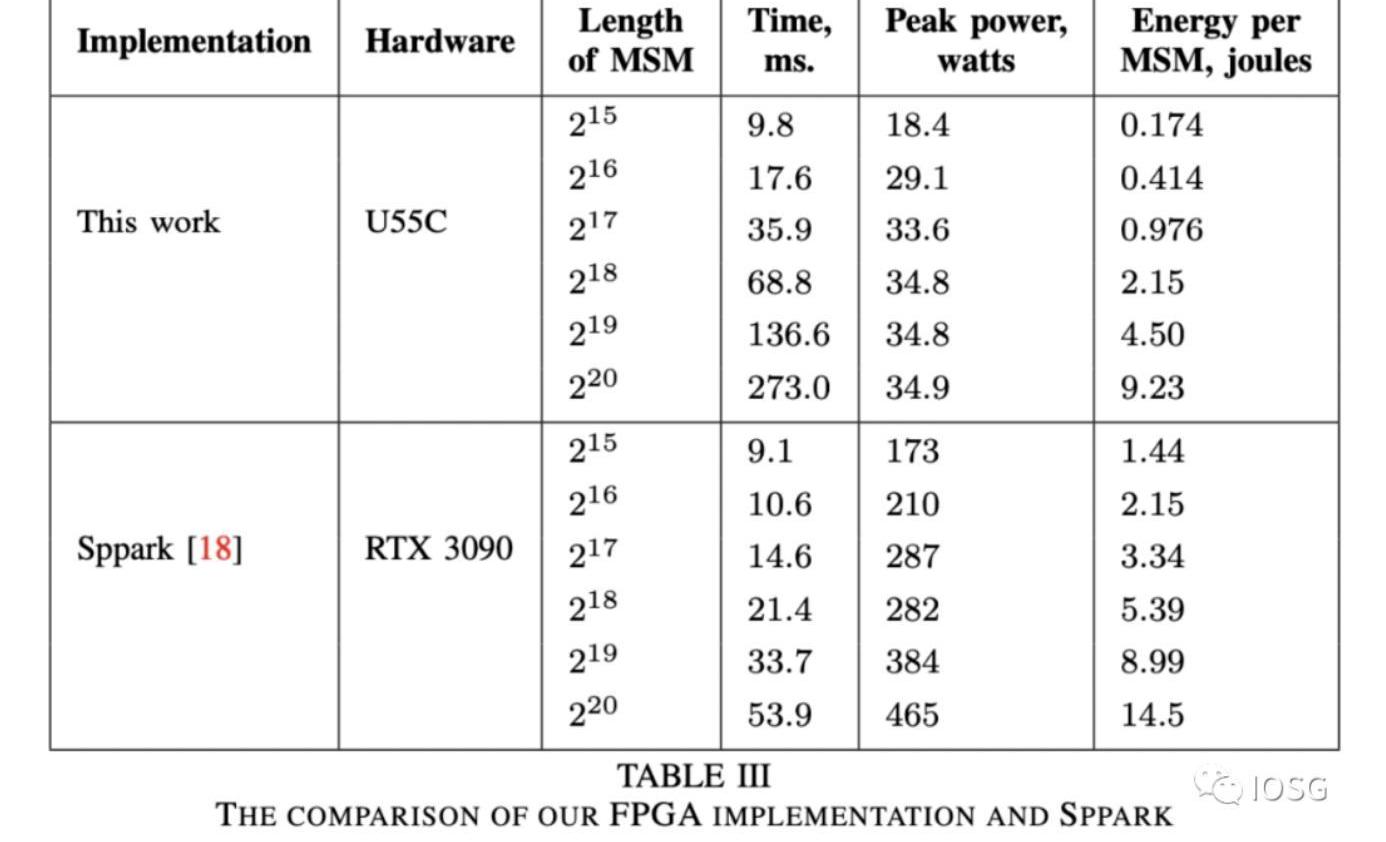
尤其是對于比特寬度更高的運算,GPU是FPGA運算速度的五倍,而消耗的電量同時也高很多。
對于普通礦工來說,性價比也是一個衡量到底使用哪一個硬件的重要的因素。無論是U55C($4795)還是VU9P($8394)來說,相比于GPU(RTX3090:$1860),價格都要高出很多。
理論層面,GPU適合并行運算,FPGA追求可編程性,而在零知識證明生成的環境下,這些優勢并不能完美適用。比如,GPU適用的并行計算是針對大規模圖形處理,雖然邏輯上和MSM的處理方式類似,但是適用的范圍與zkp針對的特定的有限域并不一致。對于FPGA來說,可編程性在多個L2的存在的應用場景并不明朗,因為考慮到L2的礦工獎勵與單個L2承接的需求掛鉤,有可能在細分賽道出現winnertakesall的局面,導致礦工需要頻繁更換算法的情景出現的可能性不高。
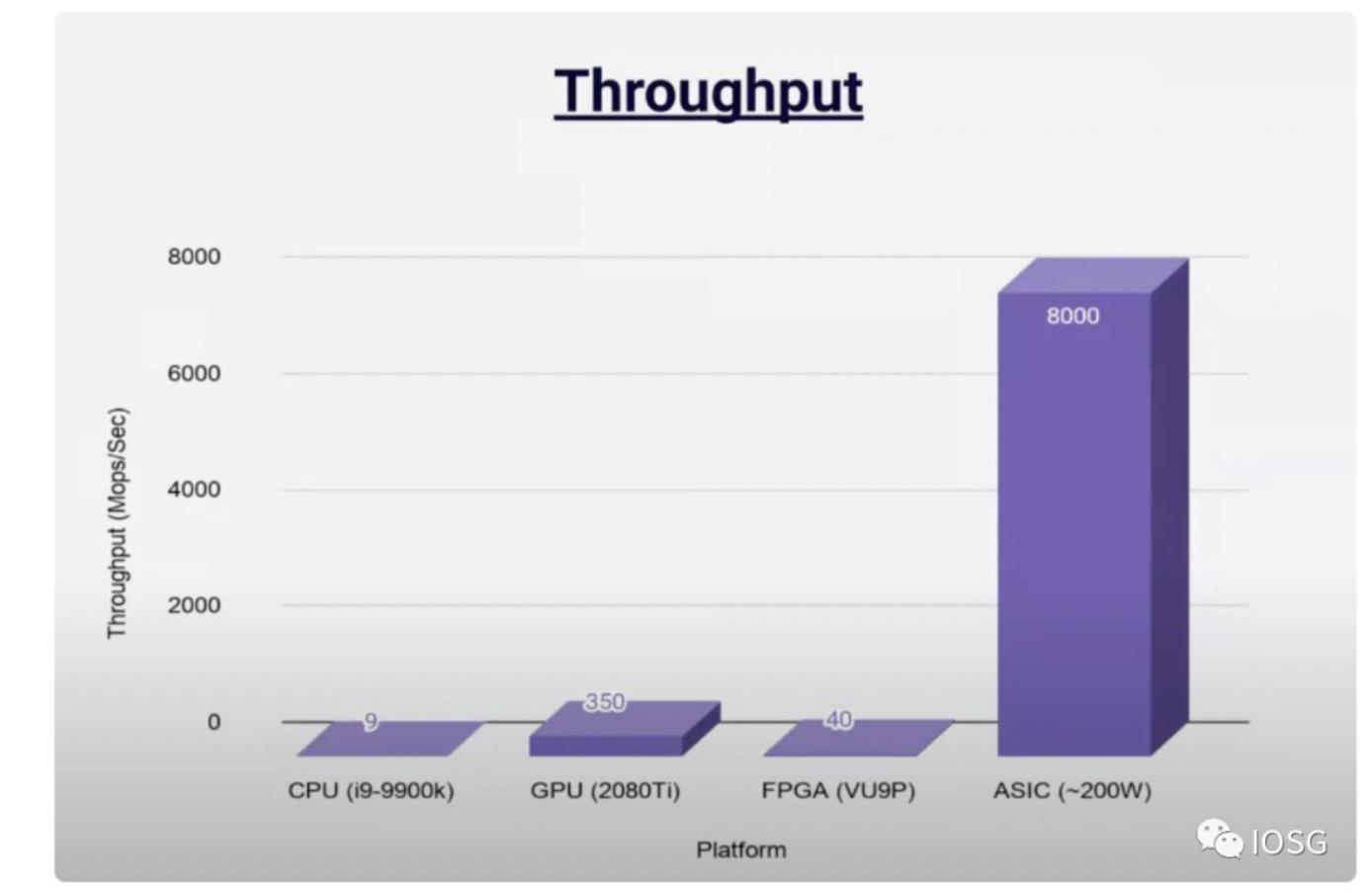
ASIC是在性能與成本方面上權衡表現較優的方案,但是否是最好的方案仍然沒有定論,其存在的問題是:
開發時間長-需經歷完整的芯片設計到芯片生產的過程,即使目前已經設計好了芯片,芯片生產也是一個冗長、燒錢并且良片率不一的過程。代工資源方面,臺積電和三星是最好的芯片代工工廠,目前臺積電的訂單已經排到了兩年后,與ZK芯片競爭代工資源的是AI芯片、電動車芯片這類web2早早做好芯片設計的已經被需求證明的產品,相比之下ZK芯片的需求并不明朗。
其次,整顆芯片的性能和單個芯片的大小,也就是人們常說的20nm,18nm是成負相關的,也就是說單個芯片越小,晶片可以容納的芯片的數量越多,即整顆的性能越高,而目前的制造高端芯片的的技術是被壟斷的,對于一些中小型的代工廠這類技術方面落后頂尖一到兩代,也就意味著從良品率以及芯片大小方面是落后于最好的代工廠的。這會導致對于ZK芯片來說,只能尋求一些次優的解決方案,當然也是在需求端不那么明朗的情況下基于成本的考慮,選擇28nm左右的非高端芯片。
目前的ASIC解決方案主要處理的是FFT以及MSM兩個常見的ZK電路中算力需求比較高的算子,并不是針對具體的一個項目設計的,所以具體運行的效率并不是理論上最高的。比如,目前Scroll的prover的邏輯電路還沒百分百實現,自然也不存在與之一一匹配的硬件電路。并且,ASIC是application-specific,并不支持后續的調整,當邏輯電路發生了變化,比如節點的客戶端需要升級,是否存在一個方案也可以兼容,也是目前不確定的。
同時,人才缺失也是ZK芯片的一個行業現狀,理解密碼學和硬件的人才并不好找,合適的人選是有同時具備較深的數學造詣以及多年的硬件產品設計以及維護經驗。
Closingthoughts-prover發展趨勢EigenDA
以上都是行業對于加速ZKP的思考與嘗試,最終意義就是運行prover的門檻會越來越低。周期性來講prover需要經歷大致的如下三個階段:
PhaseI:Cloud-basedprover
基于云的prover可以大大提高第三方prover的準入門門檻,類似于web2的aws/googlecloud。商業模式上來講,項目方會流失一部分獎勵,但是從去中心化的敘事講這是一種經濟以及執行層面吸引更多參與者的方式。而云計算/云服務是web2現有的技術棧,已有成熟的開發環境可供開發者使用,并且可以發揮云所特有的低門檻/高集群效應,對于短期內的proofoutsource是一種選擇。
目前,Ingoyama也有在這一方面的實現。但是,這依然是一個單個prover運行整個proof的方式,而在phaseII中proof可以是一種可拆分的形式存在,參與者數量會更多。
PhaseII:Provermarketplace
proof生成的過程中包含不同的運算,有的運算對于效率有偏好,有的運算則對成本/能源消耗有要求。比如MSM計算涉及pre-computation,這需要一定的memory支持不同的pre-computation上的標量顆粒,而如果所有的標量都存在一個計算機上的話對于該計算機的memory要求較高,而如果將不同的標量存儲在多個服務器上,那么不僅該類的計算的速度會提高,并且參與者的數量也會增加。
Marketplace是一種針對上述外包計算的一種商業模式上的大膽的思考。但其實在Crypto圈子里也有先例-Chainlink的預言機服務,不同鏈上的不同交易對的價格喂送也是以一種marketplace的形式存在。同時,Aleo的創始人HowardWu曾經合作撰寫過一篇DIZK,是一個分布式賬本的零知識證明生成方法論,理論上是可行的。
話說回來,商業模式上講這是一種非常有意思的思考,但是可能在實際落地時一些執行上的困難也是巨大的,比如這類運算之間如何協調生成完整的proof,至少需要在時間以及成本上不落后于PhaseI。
PhaseIII:Everyonerunsprover
未來Prover會運行在用戶本地,如Zprize有基于webassembly/andriod執行環境的ZKP加速相關的競賽和獎勵,意味著一定層面上用戶的隱私會得到確保,最重要的上-這里的隱私不僅局限于鏈上行為,也包括鏈下行為。
一個必須要考慮的問題是關于網頁端的安全性,網頁端的執行環境相比硬件來說對于安全性的先決條件更高。
除了鏈上數據鏈下證明外,以ZKP的形式將鏈下數據上傳到鏈上,同時百分百保護用戶隱私,也只有在這個Phase可能成立。目前的解決方案都難免面臨兩個問題-1.中心化,也就是說用戶的信息依然有被審查的風險2.可驗證的數據形式單一。因為鏈下數據形式多樣且不規范化,可驗證的數據形式需要經過大量的清洗/篩查,同時依舊形式單一。
這里的挑戰甚至不只是證明生成的環境,對于算法層面是否有能夠兼容,以及成本/時間/效率都是需要思考的。但是同樣需求也是無與倫比的,想象可以以去中心化的方式抵押現實生活的信用在鏈上進行借貸,并且不會有被審查的風險。
Tags:PROVERROVERARKHippo ProtocolCover ProtocolAdroverseBenchmark Protocol
DeFi數據 1、DeFi代幣總市值:396.9億美元 DeFi總市值及前十代幣數據來源:coingecko2、過去24小時去中心化交易所的交易量25.
1900/1/1 0:00:00加密銀行SilvergateBank和加密行業各大中心化交易機構如FTX、Coinbase、Crypto.com、Circle等有著極其緊密的聯系.
1900/1/1 0:00:0011月28日,廣告營銷股天下秀被滬股通減持3.27萬股,已連續3日被滬股通減持,共計81.4萬股。對此,有分析認為外資投資者對行業景氣度十分敏感,滬股通減持的原因,可能在于行業景氣度不被看好.
1900/1/1 0:00:001.“幻想”與“迷狂”:三位“炒幣者”的自述近期,隨著比特幣價格的劇烈波動,“炒幣者”群體再度受到市場的廣泛廣注.
1900/1/1 0:00:00作者:DanielLi FTX爆雷引發市場連鎖反應在交易所接連上演,且有愈演愈烈之勢。最近灰度比特幣信托負溢價升至歷史新高,可能成為行業下一個“雷區”,市場恐慌引發了新一輪大規模提幣運動,在這輪.
1900/1/1 0:00:00或許Coindesk沒能想到,自己的一篇報道在帶崩FTX后,也讓這把火燒到了自己母公司DigitalCurrencyGroup身上.
1900/1/1 0:00:00


