






 BTC/HKD+0.9%
BTC/HKD+0.9% ETH/HKD+2.71%
ETH/HKD+2.71% LTC/HKD+0.72%
LTC/HKD+0.72% DOT/HKD+2.86%
DOT/HKD+2.86% ADA/HKD+2.34%
ADA/HKD+2.34% SOL/HKD+0.65%
SOL/HKD+0.65% XRP/HKD+0.18%
XRP/HKD+0.18% DOGE/US+1.07%
DOGE/US+1.07% 
圖片來源:由無界版圖AI工具生成
本文全方位地介紹了ChatGPT的能力特征、發展歷程以及OpenAI一路走來所堅守的技術路線,并對ChatGPT出現之后NLP領域的范式轉換進行了展望,即ChatGPT開啟「文本生成+指令」的范式。
1、ChatGPT,不再「愚蠢」的人工智能
ChatGPT的相關話題應該算是繼AlphaGo以來,最出圈的人工智能熱點了。簡單來說,它是一個可以用自然語言對話的機器人,你可以問它任何問題,它都會以非常流暢、標準的自然語言回答你。不僅如此,它還能回答代碼問題、數學問題等等,你可以和它在關于任何問題上聊得不亦樂乎。
我們可以用一個經典的雞兔同籠問題來感性地認識一下ChatGPT的能力:
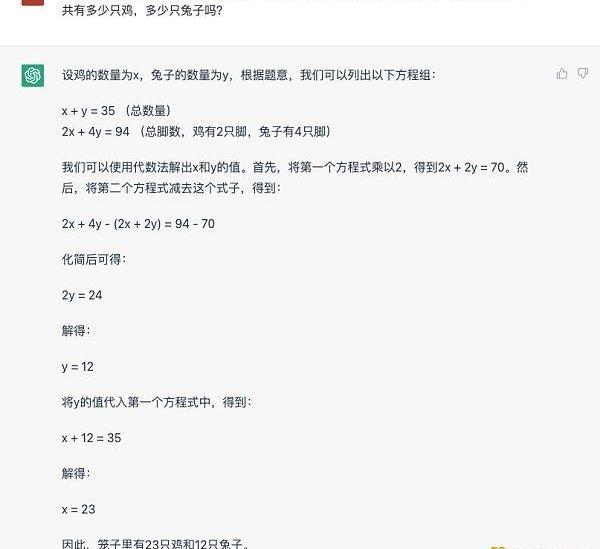
從這個回答可以觀察到幾個特點。首先是對自然語言的理解和轉換為數學問題的能力,其次它通過將一個較為復雜的推理問題分步拆解,一步步獲得最后的答案。這個能力被業內稱作「思維鏈」。接下來換一下問法,看看它會怎么回答。

從這個圖中可以發現,ChatGPT對自己所說的內容是有感知的,并且可以給出這么說的原因。另外也可以發現,它確實也會出錯,但可以通過引導的方式讓它給出正確的答案,并且會告訴你自己為什么錯了。
如果不事先告訴你這是一個人工智能模型,ChatGPT給人的感覺確實像一個真正有邏輯思維和語言交流能力的真人。它的出現第一次讓大家覺得,人工智能似乎終于能夠和人正常交流了,雖然有時候會出錯,但在交流的過程中至少沒有語言和邏輯上的障礙,它能「懂」你在說什么,并且按照人類的思維模式和語言規范給你反饋。這種非常智能的體驗感,是它突破業界小圈子,給大眾帶來沖擊感的原因。
這里還希望再次強調這種體驗感的問題,因為也許過去業界由于技術的限制,為了完成場景中的特定任務而忽略了這一點。如今ChatGPT的出現代表了人工智能不再是過去那種「有用,但是也挺蠢」的形態了。
為了更好地理解ChatGPT這種非常智能的感覺是怎么產生的,難免要從過去那種「很蠢」的人工智能說起。準確地說,ChatGPT背后使用的依然是自然語言處理技術,但卻打破了原有的范式。
要理解這一點,可以先看看目前的主流做法是怎樣的。人類交流依托的是語言,甚至也有很多人認為人類的思維也是建立在語言上的。因此,理解運用自然語言一直是人工智能的重要課題。但語言實在太復雜,因此為了讓計算機理解運用語言,通常會將這個過程拆分為很多的細分項,這就是在技術領域中常說的「任務」。舉幾個例子:
情感分析任務,針對的是理解語言所蘊含的情感傾向;
句法分析任務,針對的是分析文本的語言學結構;
實體識別任務,針對的是從文本中定位出實體片段,例如地址、名字等等;
實體連接任務,針對的是從文本中抽取出實體間的關系;
這樣的任務還有很多,都是從某個細分的側面去對自然語言進行分析、處理。這樣做有很多好處,比如有了這些拆分,就可以從不同的維度來考察一個自然語言處理系統的細分能力;也可以針對某一個細分的項專門做系統或者模型的設計等。從技術的角度來說,將一個復雜的任務拆分為很多的簡單任務確實是一種比較典型的解決復雜問題的路徑,這也是目前的主流做法。然而在ChatGPT出現之后,以馬后炮視角去看,也許在讓計算機理解并運用自然語言這條路上,這種拆分并不是最有效的途徑。
因為在單個任務上的優秀表現,并不能代表系統就掌握了自然語言。人對于人工智能體的「智能感」,是基于對它應用自然語言的整體能力而產生的,這一點在ChatGPT上有明顯的體現。雖然OpenAI沒有開放ChatGPT的API服務,外界還無法測評它在各個細分NLP任務上的具體效果,但以過往外界對它的前身GPT-3、InstructGPT等模型的測試情況表明,對于某些特定的任務,一個用專門數據精調過的小模型,確實可以獲得更好的效果。但這些在單個任務上有更好表現的小模型,并沒有引起很大的出圈效應。歸根結底,是因為它們只有單一的能力。單個的能力出眾并不能代表它們具有了理解和運用自然語言的能力,從而也無法獨自在實際應用場景中發揮作用。正因如此,通常在一個真實的應用場景中,都是多個具有單點能力的模塊經過人為的設計拼湊而成,這種人為的拼湊方式是過去的人工智能系統讓人感覺并不智能的原因之一。
從人類理解和運用自然語言的視角去看,這個現象其實很好理解。普通人在理解、運用自然語言的時候,并不會在腦內將它拆分為很多步不同的任務,逐個任務進行分析,然后再匯總,這不是人類使用自然語言的方式。就好比一個人,在聽到一句話的時候,并不會對它的句法結構、實體內容與關系、情感傾向等這些內容逐一分析,然后拼湊出這句話的含義,人對語言的理解過程是一個整體過程。再進一步,人對這句話的整體理解,會以自然語言的形式,通過回復的方式整體地表現出來。這個過程并不是像人工智能系統那樣,拆分單個任務,然后逐一輸出情感分析的標簽、實體信息的片段、或是別的某個單個任務的結果,然后用這些東西拼湊出回復。
而以ChatGPT為代表,GPT系列模型所做的事情才真正接近了人類理解和運用語言的能力——直接接收自然語言,然后直接回復自然語言,并保證了語言的流暢性與邏輯性。這是人與人的交流方式,所以大家對它抱以「很智能」的體驗感。也許很多人會認為,如果能做到ChatGPT這樣當然很好,過去那種對任務的拆分是因為技術的限制不得已而為之。從技術應用的視角來看,這樣迂回的方式當然是需要的,這種方法也在很長的一段時間內被采用,并且確實也能夠解決很多實際場景中的問題。但如果回顧GPT系列模型的發展過程,就會發現OpenAI「賭」了另一條路,并且他們「賭」贏了。
NA Chain卡俄斯測試網節點正式啟動:官方消息,NA(Nirvana)Chain卡俄斯測試網節點今日正式啟動,200臺服務器于7月5日上午11:00(UTC+8)正式開機,參與卡俄斯測試網運行。目前,參與本次測試網節點啟動的200臺服務器運行良好。數據顯示,應用主鏈POW-FLOW每60秒產出一次,邏輯鏈DPoS每6秒產出一次;截止今日發稿16時,應用主鏈POW-FLOW產出300枚代幣,邏輯鏈DPoS產出3000枚NAC代幣。
據悉,NA(Nirvana)Chain主網預計在10月4日左右準時上線,目前正在大力布局節點合作,通過這次服務器的開機,NA(Nirvana)Chain將持續擴大區塊鏈市場份額與影響力。[2021/7/5 0:28:20]
2、OpenAI的「賭局」
GPT初代,一切開始的地方
早在2018年,OpenAI就發布了最初版本的GPT模型,從OpenAI公開的論文可以了解到,這個模型采用了12層的TransformerDecoder結構,用了大約5GB的無監督文本數據進行語言模型任務的訓練。雖然初代GPT模型采用的就已經是生成式的預訓練,但使用的是無監督預訓練+下游任務微調的范式。這一范式其實并不是什么新的發明,它在CV領域已經有比較廣泛的應用,只是由于當年ELMo模型的出色表現,把它重新「介紹」到了NLP領域。
GPT模型的出現在那一年確實引來了一些業內的關注,但它并不是那一年的C位主角。因為就在同年,Google的BERT模型橫空出世,以優異的效果吸引了幾乎全部的目光。
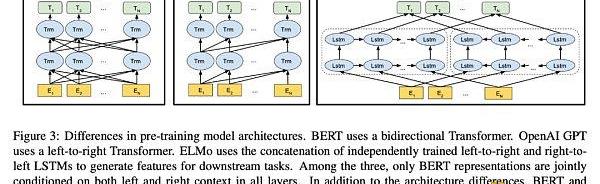
圖片來自BERT論文,從圖示中可以一窺當年BERT對標的就是GPT,并引以為傲地指出雙向編碼能力。
BERT模型雖然也是采用和GPT一樣的Transformer模型結構,但它幾乎就是為「無監督預訓練+下游任務微調」的范式量身定制的模型。和GPT相比,BERT所使用的掩碼語言模型任務雖然讓它失去了直接生成文本的能力,但換來的是雙向編碼的能力,這讓模型擁有了更強的文本編碼性能,直接的體現則是下游任務效果的大幅提升。而GPT為了保留生成文本的能力,只能采用單向編碼。
以當年的眼光來看,BERT絕對是一個更加優秀的模型。因為既然BERT和GPT兩者都是采用「預訓練+微調」的范式,并且下游任務依然是分類、匹配、序列標注等等「經典」的NLP任務形式,那么像BERT模型這種更注重特征編碼的質量,下游任務選一個合適的損失函數去配合任務做微調,顯然比GPT這種以文本生成方式去「迂回地」完成這些任務更加直接。
從BERT模型出來以后,「無監督訓練+下游任務微調」的范式便奠定了它的霸主地位,各類沿著BERT的思路,琢磨「如何獲得更好的文本特征編碼」的方法大量涌現,以至于GPT這個以生成式任務為目標的模型顯得像一個「異類」。馬后炮地說,如果當時OpenAI「順應大勢」,放棄生成式預訓練這條路,也許我們要等更長的時間才能見到ChatGPT這樣的模型。
GPT-2帶來的希望
當然,我們現在見到了ChatGPT,所以OpenAI沒有放棄生成式預訓練的路線。實際上堅持的「回報」隱約出現在了第二年,也就是2019年。OpenAI發布了有48層Transformer結構的GPT-2模型。在發布的論文中,他們發現通過無監督數據配合生成式訓練后,GPT展示出了零樣本的多任務能力。而奇妙的是,這些多任務的能力并不是顯式地、人為地加入到訓練數據中的。用通俗的話來舉個例子,GPT-2其中一個展示出來的能力是做翻譯,但令人吃驚的是,通常專門用來做翻譯的模型是需要大量的平行語料進行監督訓練,但GPT-2并沒有使用這種數據,而僅僅是在大量的語料上進行生成式的訓練,然后它就「突然」會做翻譯了。這個發現或多或少地帶有點顛覆性的意味,它向人們展示了三個重要的現象:
想讓模型去完成一種NLP任務,也許并不需要和任務匹配的標注數據。例如GPT-2訓練時沒有用標注的翻譯數據,但它會做翻譯;
想讓模型去完成一種NLP任務,也許并不需要和任務匹配的訓練目標。例如GPT-2訓練的時候并沒有設計翻譯任務和相關的損失函數,它只是在做語言模型任務。
僅僅用語言模型任務訓練的模型,也可以具有多任務的能力。例如GPT-2展現出了翻譯、問答、閱讀理解等等的能力。
雖然以現在的眼光來看,當時的GPT-2所展示出來的各種能力還比較初級,效果距離使用監督數據微調后的一些其它模型還有明顯的差距,但這并沒有妨礙OpenAI對它所蘊含的潛在能力充滿期待,以至于在論文摘要中的最后一句話中,他們提出了對GPT系列模型未來的期望:
“Thesefindingssuggestapromisingpathtowardsbuildinglanguageprocessingsystemswhichlearntoperformtasksfromtheirnaturallyoccurringdemonstrations.”
后來一系列事情的發展也證明了他們確實是一直朝著這個promisingpath的方向在前進。如果說在2018年,GPT初代模型出來的時候,GPT的生成式預訓練還面臨著被BERT這類以「提取特征」為目地的預訓練模型在各方面碾壓,那么在GPT-2中的發現,給了生成式預訓練一個BERT類模型無法替代的潛在優勢,即語言模型任務所帶來的多任務能力,且這種多任務能力是無需標注數據的。
跨鏈交易協議RAIFinance將集成Chainlink預言機喂價:基于Polkadot區塊鏈的跨鏈交易協議RAIFinance宣布將與Chainlink集成,為開發人員和用戶在其推出的基于AMM的去中心化交易所進行資產交換時提供安全可靠的價格預言機的服務。Chainlink支持的去中心化價格預言機可用于在RAIFinance之上根據資產估值變化等市場變動創建自動交易策略。
從匯總的加密貨幣價格開始,Chainlink將為RAIFinance提供準確的鏈外數據提要訪問。RAIFinance是基于波卡的跨鏈資產交易協議,旨在向現有的去中心化金融生態系統提供解決流動性不足、創建DeFi資產等問題的解決方案。[2021/2/16 19:51:49]
當然,在那個時間點上,生成式的技術路徑依然面臨風險和挑戰。畢竟當時的GPT-2在各任務上的表現還是差于經過微調的模型,這導致了GPT-2雖然有著翻譯、摘要等等能力,但效果太差以至于無法實際使用。因此,如果在當時想要一個可用的翻譯模型,最好的選擇依然是老老實實用標注數據訓練一個專門用來翻譯的模型。
GPT-3,數據飛輪的開始
從ChatGPT時代往回看,也許OpenAI在GPT-2中的發現確實堅定了他們對GPT系列模型的信心,并決定加大研發投入力度。因為在隨后的2020年他們發布了1750億參數量的GPT-3,一個即便以現在的眼光去看也大得讓人驚嘆的模型。雖然OpenAI沒有明確公開訓練這個模型的費用,但大家的估算是當時花了1200萬美元。同時公開的還有一篇長達60多頁的論文,其中詳細闡述了這個新的龐然巨物所展示出來的新能力。最重要的發現莫過于論文標題中所說的,語言模型具有小樣本學習的能力。
小樣本學習是一個機器學習領域的專業術語,但它有著很樸素的理念,即「人類是可以通過少量的幾個例子就學會一個新的語言任務」。想象一下在語文課上學習怎么掌握「把」字句換成「被」字句樣的情形,老師會給出幾個例子,同學們就能夠掌握這項能力。
但對于深度學習模型來說,它通常需要學習成千上萬的例子才能掌握一項新的能力,但大家發現GPT-3卻像人類一樣具有類似的能力。而且重點在于,只需要給它展示幾個例子,它就會「有樣學樣」地完成例子給出的任務,而不需要進行額外的訓練。后來的研究表明,這種能力是巨型模型所特有的,被業內叫做「在上下文中學習」的能力。

GPT-3論文中所展示的英語翻譯法語的Incontextlearning能力。
實際上,小樣本學習能力本身并不是很驚人的發現。畢竟業內一直都在對小樣本學習進行研究,很多專攻小樣本學習的模型都有出色的小樣本學習能力。但GPT-3展示出來的這種「在上下文中學習」的小樣本能力卻非常出人意料,其原因也和GPT-2所展示的多任務能力一樣:
GPT-3并沒有為了獲得小樣本的能力而在訓練數據、訓練方式上做特別的設計,它依然只是一個用語言模型任務訓練的生成式模型;
GPT-3的小樣本能力是以「在上下文中學習」的方式展現出來的。換句話說,想讓它獲得新的能力,不需要對它再訓練,而只需要給它看幾個示范的例子。
除了這個能力以外,GPT-3還展示出了優秀的文本生成能力,相比GPT-2,它生成的內容更加流暢,而且可以生成很長的內容。這些能力綜合體現在一個模型上,讓GPT-3在當時成為了大家的關注焦點,它也成為OpenAI正式對外提供服務的模型。
但隨著這個模型服務的開放,越來越多的人嘗試使用這個模型。從這時起,OpenAI通過開放給公眾的方式,同時也在收集著更具有多樣性的數據,這些數據在后來的模型迭代中也發揮著重要的作用。自此GPT系列模型的數據飛輪便轉動了起來,越多優質的用戶數據,迭代出效果越好的模型。
與ChatGPT不同的是,GTP-3并不是采用對話的形式交互的模型,而是一個文本的續寫模型,因此它并不具備如今的ChatGPT所擁有的多輪對話能力。但它已經能夠干很多的事情,例如編寫故事、給郵件做自動補全等等。但同時,大家也慢慢發現了一些問題,例如它會一本正經地輸出不符合事實的內容,并且會輸出一些有害的言論等等。這是這種文本生成模型最突出的弊端,雖然經過多次迭代,但ChatGPT如今也依然面臨類似的問題。
CodeX,讓計算機自己寫代碼
OpenAI在對GPT-3的研究中還有一個意外的發現,它能夠根據一些注釋生成很簡單的代碼。因此在隨后的2021年,他們對生成代碼這件事情進行了專門的研究投入,并發布了CodeX模型。它可以看作是一個有著代碼專精能力的GPT模型,能夠根據自然語言輸入生成比較復雜的代碼。
從外部視角來看,我們無法判斷代碼生成的研究與GPT系列模型的研發是否在同時進行。但放在當時,讓模型具有生成代碼的能力,從實用化的角度來說確實更加具有意義,畢竟GPT-3還未擁有如今ChatGPT這般強悍的能力。另一方面,讓模型去生成代碼也能規避它生成有危害文本內容帶來的風險。
在CodeX論文中提及了幾個要點,首先是讓經過文本數據預訓練的GPT模型在專門的代碼數據上訓練確實能夠明顯提升模型對代碼的理解和輸出能力。其次是論文中用的是一個120億參數的「小」模型,這個信息從側面反映出OpenAI內部除了對外開放接口的1750億參數的GPT-3模型外,還有別的不同大小的模型版本。
而加入代碼訓練,讓模型獲得理解和生成代碼的決定,原本的初衷也許只是希望GPT能夠多一種應用場景。它看似與GPT系列模型在理解和運用自然語言的能力沒有太大的聯系,但根據后續的研究,增加對代碼數據的訓練很有可能觸發了后來的GPT模型在自然語言上的復雜推理和思維鏈的能力。
KuCoin與Chainalysis達成合作,加強合規和安全機制:6月1日,交易所KuCoin宣布與區塊鏈分析公司Chainalysis達成合作,以向用戶提供一系列加密貨幣交易工具和服務,從而繼續致力于加密行業的業務合規和用戶安全。(BTCManager)[2020/6/2]
也許在OpenAI做CodeX之初并沒有預料到會有這樣的結果,但就像他們一直使用文本生成任務來做GPT模型,然后在GPT-2和GPT-3中「解鎖」了「多任務的能力」和「在上下文中學習的能力」那樣,代碼數據的引入又一次讓他們獲得了意料之外的收獲。雖然看上去似乎有一些偶然,但對技術路線的前瞻性認知,加上堅持與持續的投入顯然是一個至關重要的因素。
InstructGPT,讓GPT好好說話
在前面我們提到了GPT-3雖然已經有很強的能力,但上線以后隨著使用的人越來越多,也發現了很多問題,最嚴重的應該要數「一本正經地胡說八道」和「輸出帶有危害性的內容」這兩點了。雖然在2021年OpenAI似乎暫時將重點放在了讓模型理解和生成代碼這件事情上,但他們應該一直在嘗試解決GPT-3的這些問題。
在2022年初,OpenAI發表了InstructGPT的論文,從中我們可以一窺解決這些問題的方法。論文的核心理念是讓模型接受人類的教導,這一點在標題中就已經開宗明義了。
GPT-3之所以會出現「一本正經地胡說八道」和「輸出有害的內容」這樣的問題,其根源來自于它所使用的訓練數據。像GPT-3這樣的龐然大物,對數據的需求量是海量的。我們從GPT-3的論文中可以找到它的數據來源,大致可以劃分為三類:網頁內容、百科內容以及書籍。雖然網頁內容的量非常大,但也非常「臟、亂、差」,自然會包含很多非真實性和有害的內容。GPT-3在這些數據上進行訓練,自然也就學到了這些東西。
但作為一款對外提供服務的產品,GPT-3的回答應該更小心一些。要解決這個問題,其中的一難點在于怎么去定義模型應該怎么說話。因為生成模型的輸出內容是自然語言本身,而不是一個分類的標簽或一個實體名詞這種有明確的、客觀對錯的內容。沒有明確的對錯,就導致無法像訓練經典的NLP模型那樣直接針對目標設計訓練任務。
而InstructGPT給出的解決思路是非常直接的,既然對于「好的回答」這個評價指標有很多不同的影響因素,這些因素又相互交織在一起,那就讓人來教它怎么寫回答。因為人類是比較善于處理這種「既有明確的要求,又有模糊的范圍」的問題的,讓真人寫一些「優秀范例」,讓模型去學習這些「優秀范例」,這正是InstructGPT提出的總體思路。
具體而言,InstructGPT提出了兩個階段的路徑來讓GPT學習人類給出的「優秀范例」,第一階段是監督學習,第二階段是強化學習。在第一階段中,讓真人根據不同的Prompt寫真實的、無害的、有用的回答。實際操作過程中,為了保證這些內容的質量,會給寫回答的標注人員一些規范性的指引,然后讓已經經過預訓練的GPT模型在這些人類編輯的數據上繼續訓練。這一階段可以看作是對模型的一種「規訓」,用一個不嚴謹的類比來說,就像語文老師讓你默寫優秀范文那樣。
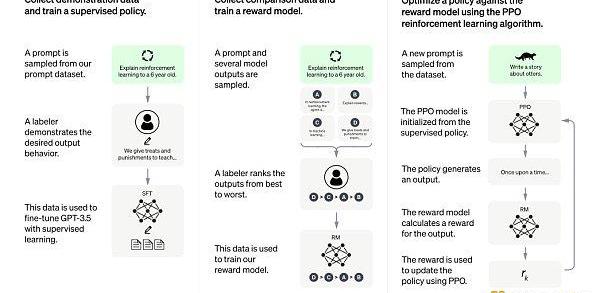
圖片來自InstructGPT論文,提出通過監督式的指令微調+人類反饋的強化學習來讓模型的輸出變得合理。
第二階段是強化學習,技術上分為兩步。第一步是讓被「規訓」后的模型根據不同的Prompt生成多個不同的回答,并由人來給這些回答按照好與差的標準來排序。然后用這些標注了優劣之分的數據訓練一個打分模型,讓它可以自動給更多的數據進行排序打分。強化學習階段的第二步就是利用這個打分模型作為強化學習中的環境反饋,以策略梯度的方式對已經「規訓」后的GPT模型進行訓練。整個第二階段的過程可以看作是對模型的一種「強化」,再用一個不嚴謹的類比來說,就像語文老師給你寫的作文打分,讓你從分數中分辨什么是好與不好,然后不斷進步。
因此,用一種非常不嚴謹,但普通人或許也能夠理解的方式來說,InstructGPT先是讓一個「口無遮攔」的GPT通過「默寫人類的優秀范文」的方式初步學會「好好說話」,然后再「給它獨自寫出來的東西打個分,讓它回去好好領悟,繼續進步」。當然,在技術上牽涉事情會更復雜一些,比如「優秀范文」的具體規范和數量等數據上的問題,以及強化學習中打分模型的選擇,算法參數的設置等算法上的問題,都會對最后的效果產生影響。但最終的結果表明,這種方式是非常有效的,論文中也指出一個通過上述方式訓練出來的13億的小模型,效果就能夠超過沒有經過這種訓練的更大的模型。
另外論文中還有一些非常值得一提的內容。首先是關于Prompt的一些發現。InstructGPT訓練時所使用的Prompt主要由兩部分構成,一部分是專門的AI訓練師編寫的,另一部分自來OpenAI的模型在線服務期間,由用戶使用中編寫的內容,這時數據飛輪的作用就體現了。可以發現,無論是哪種,這些Prompt都是由真人寫出來的,雖然文章中沒有對這些Prompt的具體涵蓋范圍、分布情況以及提問的方式展開詳細的分析,但可以合理地猜測這些Prompt具有一定的多樣性和較高的質量。其實文章中對比了使用這些真人編寫的Prompt訓練的模型和使用一些開源NLP任務數據集中構建的Prompt訓練出來的模型,結論是由真人編寫Prompt訓練出來的模型,給出的答案更加能被評測的人接受。
另外一點是關于訓練好的模型對新的Prompt的泛化能力的問題,可想而知的是,如果訓練完成的模型無法產生Prompt的泛化能力,那么現在ChatGPT所表現出來的,幾乎百問百答的能力是不太可能產生的。因為在模型做微調的階段,即便是再多的數據,也不可能把人們有可能會輸入的內容都覆蓋完整。而InstrctGPT論文中點明了文中所采用的方法是可以產生Prompt的泛化能力的。
金色財經現場報道 Blockgame聯合創始人及Topchain核心成員Emily Lee:太平洋地區是游戲的重要市場:金色財經獨家現場報道,在火幣Pro舉辦的Blockchain Festival千人大會上,Blockgame聯合創始人及Topchain核心成員Emily Lee提供的2018年報告顯示,在游戲上,全球23億玩家花費1.04億美元。這比上一年增長了16%,數字游戲收入將占全球市場的91%。所以這可能是第一次,超過一半的收入來自移動領域,自從iPhone手機在2007年推出以來,我們發現用戶比以前花費了更多時間在游戲上,這對新一代人是很正常的。在區域上,北美、歐洲、日本及太平洋地區有一些重要的全球游戲市場,我們認為太平洋地區是非常重要的一部分,這是因為一些新興市場諸如印度、南亞等地區關注游戲的用戶會大量增長。[2018/5/25]
之所以花了更多的文字對InstructGPT做介紹,因為根據ChatGPT官方頁面的介紹,InstructGPT中的方法正是用來訓練ChatGPT的方法,不同的只是ChatGPT使用了對話式的數據組織方式。
GPT-3.5時代和ChatGPT的誕生
在隨后的時間內,OpenAI發布了多個被稱為GPT-3.5系列的模型,雖然這些模型并未有相關的論文跟隨發表,但根據這篇文章的分析,GPT-3.5系列應該是融合了OpenAI在GPT-3時代積累的技術、數據以及經驗開發出來的。由于沒有詳細的官方公開信息參考,關于這些模型的具體資料,外界主要是通過分析使用的體驗、相關的技術論文以及OpenAI的API文檔介紹來進行推測。
根據分析,GPT-3.5系列的模型有可能并不是在GPT-3上繼續微調而來,而很可能是將代碼和自然語言的數據融合在一起,重新從零開始訓練了一個基礎模型。這個模型可能比GPT-3的1750億參數量更大,它在OpenAI的API中被命名為codex-davinci-002。然后在這個基礎模型上,通過指令微調和人類反饋得到了一系列后續的模型,包括ChatGPT。
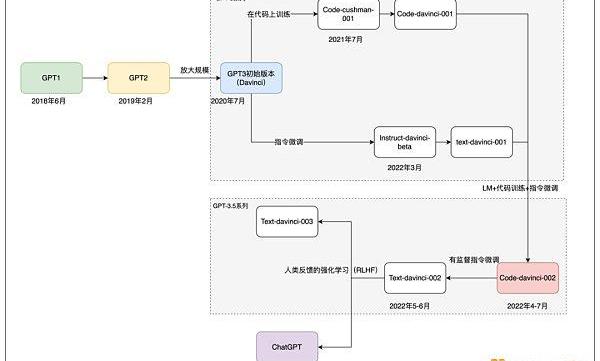
GPT系列模型的發展路徑。
簡要地說,從code-davince-002這個模型開始,經過有監督的指令微調得到text-davinci-002。以及后續的text-davinci-003和ChatGPT,也是在GPT-3.5系列的某個模型上通過指令微調以及人類強化學習反饋得到的。并且text-davinci-003和ChatGPT都是在2022年11月發布的,不同的是text-davinci-003和GPT-3一樣,是一個文本補全模型。而根據ChatGPT的官方介紹,它是通過將過往的數據處理成對話交互的形式,并增加了新的對話數據訓練出來的。
至此,我們大致回顧了OpenAIGPT系列模型從2018年的初代GPT到現在的ChatGPT,一路發展迭代的過程。在這個過程中,OpenAI一直保持著對生成式預訓練模型這一技術路徑的「執拗」,并且也一直從不斷發展的NLP技術中吸納新的方法,從最初的Transformer模型結構,到后來的指令微調等技術的出現,這些因素共同促成了如今ChatGPT的成功。有了對GPT系列模型發展的了解,我們可以再回過頭來看看如今的ChatGPT。
3、走近再看ChatGPT
在第一章節中我們闡述了ChatGPT出圈的原因主要是:「它以流暢、符合邏輯的自然語言來反饋人類對它輸入的自然語言」,從而給與它交流的人帶來了很強的「智能感」。在第二章節中通過回顧GPT系列模型的發展歷史來了解ChatGPT成功之路。而這一章節會嘗試以盡可能讓圈外人都能理解的方式,稍微深入一些技術的內容,并且探討一下當前的一些大型文本生成式模型為什么未能做到相同的效果。這一部份的主要參考來自于《深入理解語言模型的突現能力》和《拆解追溯GPT-3.5各項能力的起源》這兩篇文章以及相關的一些論文,建議希望詳細了解細節的讀者閱讀原文。
雖然在第一章中指出,ChatGPT所帶來的驚艷效果是由許多不同的NLP任務綜合體現出來的,但在分析它背后的技術時,還是通過將它的能力進行拆解會更加清晰明了一些。總體而言,ChatGPT所體現出來的能力可以大致劃分為以下幾個維度:
-文本生成的能力:ChatGPT的所有輸出都是即使生成出來的文本,所以文本生成的能力是它最基本的要求。
這一項能力實際上是來自于它的訓練方式,ChatGPT在預訓練時,是一個標準的自回歸語言模型任務,這是OpenAI所有GPT系列模型的基底。所謂的自回歸語言模型任務,通俗的理解是這樣的:它可以根據已經輸入的文本,預測下一個token應該是什么。這里所說的token,所代表的是模型所使用的最小單位的字符片段,它可以是字,也可以是詞,甚至是字母。但現在的方法通常采用的是子詞。但不論是哪種,自回歸語言模型任務的基本思路都是根據已經輸入的文本,預測下一個要輸出的文本是什么,就像下圖的例子中那樣:
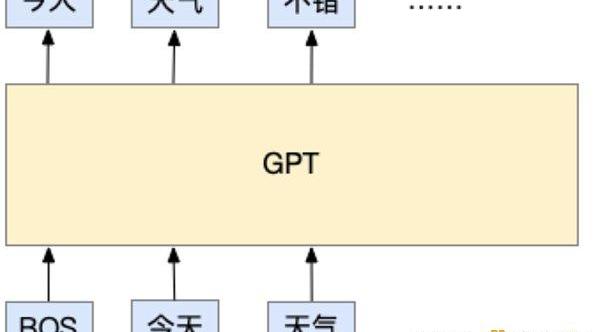
這個例子中,BOS代表了輸入的開頭,而每個token是一個詞,GPT模型根據輸入的「今天」和「天氣」兩個詞,預測下一個要輸出的是「不錯」。
在訓練的時候,會準備很多文本數據,比如網頁上的文章、各類書籍等等,只要是正常的文字內容,都可以用來訓練。值得說明的是,這種數據不需要進行額外的人工標注,因為這類數據本來就是人寫的,模型要做的事情就是根據這些人寫出的文本,去學習「給定了前面的文字,接著這些文字后面這個地方應該是什么」的問題。這便是業內所稱的「無監督訓練」,實際上模型并不是真的沒有監督,只是它的數據不需要額外的人工標注。也正因為這個任務是不需要額外標注的,因此可以「免費」獲得大量的數據,得益于互聯網的普及,可以「輕松地」獲得海量的由真人寫出的文本內容用來訓練。這一點也是GPT系列模型的特點之一,用海量的數據,去訓練很大的模型。
區塊鏈數據基金會(Blockchain DATA Foundation)和藍色光標達成戰略合作:近日,區塊鏈數據基金會宣布與藍色光標傳播集團達成戰略合作,雙方將攜手共建藍色光標昆侖堂研究院的營銷區塊鏈實驗室。雙方將展開針對DATA項目在數字營銷領域數據反欺詐方面的技術落地合作。DATA項目是以區塊鏈為基礎,以AI技術和P2P移動存儲架構為驅動的去中心化終端數據信用協議。[2018/4/27]
那么在我們使用ChatGPT的時候,它是怎么工作的呢?其實也和它的訓練方式一樣,模型會根據我們在對話框里輸入的內容,去預測接在這些內容的下一個token是什么,得到這個token后,會將它與前面的內容拼接成一個新的文本給模型,模型再預測下一個token,如此反復,直到滿足某個條件后停止。這個停止的條件有很多不同的設計方式,比如可以是輸出的文本達到特定的長度,又或者是模型預測出某個用來代表停止的特殊token。另外值得一提的是,模型預測下一個token時,其實背地里是一個采樣的過程。換句話說,模型在預測token時,輸出的其實是所有可能出現的token的概率,然后從這個概率分布里采樣一個token。因此,在使用ChatGPT時,會發現即便對于相同的輸入,它的輸出每次也會不一樣,因為在背地里它采樣了不一樣的token作為輸出。
了解這些之后,可以再回過頭來思考一下模型在學什么。它在學習怎么回答問答嗎?又或者說它在學習怎么理解自然語言所蘊含的信息、邏輯、情感?還是說它在學習海量的知識?從訓練任務的設計來看,似乎都沒有,它只是從海量的文本數據里,學習了「根據輸入的這些文本,一個人類在后面會接著寫什么」這件事。但正是這樣的模型,在「進化」到ChatGPT時,它卻掌握了豐富的知識、復雜的邏輯推理等等,它似乎掌握了一個人類運用語言所需要的幾乎所有的能力。這是一件非常神奇的事情,它的「進化」歷程將會在下一章節中做更加深入的介紹。
-豐富的知識儲備:ChatGPT能夠正確回答非常多的問題,包括歷史、文學、數學、物理、編程等等。因為目前版本的ChatGPT并沒有利用外部知識,因此這些知識的內容是「儲存」在模型內部的。
ChatGPT所擁有的豐富知識儲備,來自于它的訓練數據,以及它足夠大的體量,以便學會這些內容。雖然官方并沒有公開ChatGPT所使用的訓練數據的具體細節,但從它的前身GPT-3的論文可以推測,這些數據大致可以分為三個大的范疇:網頁內容、書籍內容以及百科內容。可想而知的是,這些內容天然地蘊含了大量的知識,百科和書籍自然不必說,而網頁內容也包含了許多新聞、評論、觀點等,并且網頁也包括了很多專門的問答垂直類網站,這些都是ChatGPT的知識來源。在官方的介紹里指出ChatGPT無法回答2021年以后發生的事情,因此合理的猜測是訓練的數據收集截止到2021年。
但數據量只是其中一個方面,要讓模型「掌握」這些數據,其自身的體量是不可能小的。以GPT-3為例,它有1750億參數,可以粗淺地理解為,這些數據的內容以及模型的各項能力,都以這一個個參數的具體數值的形式,固定在了訓練完成的模型中。感性的理解是,假設一個模型只有1個參數,那它什么也干不了。更嚴謹的分析和對比可以參考這篇論文《HolisticEvaluationofLanguageModels》的測評,方向性的結論是越大的模型,在需要知識來完成的任務上表現得越好。論文地址:https://arxiv.org/pdf/2211.09110.pdf
-邏輯推理與思維鏈的能力:從第一章圖片中的雞兔同籠的例子可以看出,ChatGPT具有很強的邏輯推理能力。并且它能夠將復雜的內容,通過拆解,分成多個小的步驟,一步步地進行推理,獲得最后的答案,這種能力被稱為思維鏈。
從前面的介紹我們知道,模型在訓練的時候并沒有針對邏輯推理以及思維鏈做特定的設計。而當前的主流觀點認為,邏輯推理和思維鏈很可能和兩個因素相關,第一個是模型的體量,第二個是模型是否在代碼數據上進行過訓練。
關于模型體量與推理、思維鏈能力的關系,在《深入理解語言模型的突現能力》中有對應的介紹。下面這張圖展示了思維鏈能力與模型體量的關系。
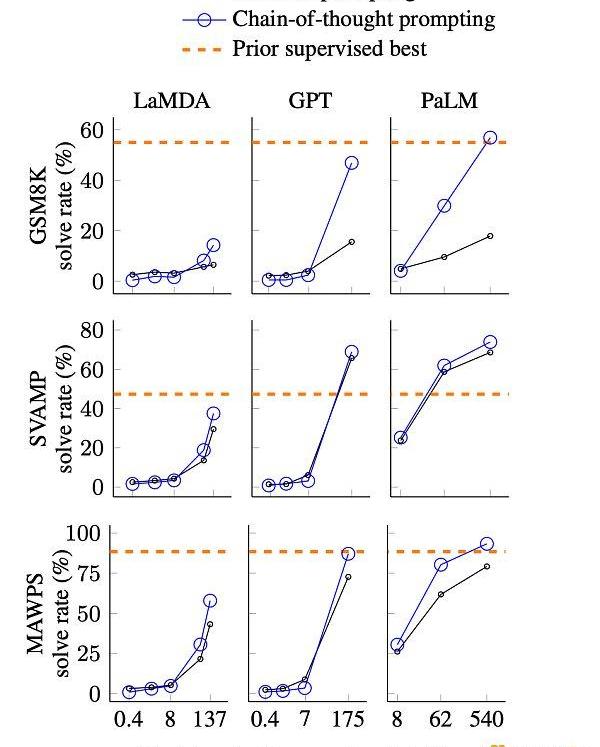
不同模型不同尺寸的思維鏈效果對比,圖來自論文。GSM8K,SVAMP和MAWPS是三個需要邏輯推理的數學應用題數據集,LaMDA,GPT和PaLM分別是3個不同的模型。
簡要地說,圖表中給出了三個不同的模型,在三個數學應用題數據集上的答對率。而值得關注的是以下幾個方面:
思維鏈的能力在模型體量夠大的時候產生了效果上的突變;
思維鏈的能力在模型夠大的前提下,效果超過了標準的指令方法;
思維鏈的能力在模型夠大的情況下,可以接近甚至超過有監督的方法。
用通俗的話來說,就是在模型足夠大的時候,思維鏈的能力突然展現了出來,能夠達到、甚至超過那些在推理數據集上專門進行有監督訓練的模型。這個圖也許部分解釋了現在我們看到的ChatGPT所具有的優異推理和思維鏈能力。
而另一個關于推理以及思維鏈能力的產生因素,與模型是否在代碼數據上做過訓練有關。目前這一點只是一個推論,《拆解追溯GPT-3.5各項能力的起源》中的分析表明體量類似的大型模型,沒有在代碼上做過訓練的話,只有很弱或幾乎沒有思維鏈和推理能力。而ChatGPT確實是在代碼數據上進行過訓練的,這一點從它能夠理解并生成代碼也可以看出來。在第二章回顧發展歷程中提到了,OpenAI在2021年就發布了專門針對代碼的CodeX模型,將代碼數據加入GPT的訓練數據應該就是從那時開始的。
-按照人的提問或者指令給予回復的能力:ChatGPT除了可以用狹義的基于「問答」形式的交互以外,還能夠按照輸入的要求進行回復。例如,在應對「幫我寫一封信」這類指令式的要求時,它同樣也展現出了優秀的能力。這種能力讓它不僅是一個提供答案的「高級搜索引擎」,更是一種可以用自然語言來交互的文字處理工具。
雖然目前大眾普遍把目光聚焦在將ChatGPT作為一種類搜索引擎的工具,但查閱相關知識并給予回答并不是它的唯一能力。實際上,單就ChatGPT本身而言,回答知識性的問題并不是它的強項,畢竟它本身的訓練數據被定格在了2021年。即便用更新的數據去訓練,但它終究跟不上時事的變化,因此要將它用作知識性的問答工具,還是需要與搜索引擎等外部知識源做結合,就像現在Bing做的一樣。
但換一個角度來看,ChatGPT像是一個「語言完備」的文本工具,也就是它能夠按照你給它的要求,完成指定的、可以用文本形式表達出來的內容,就像下面這個例子。

按照給定的計劃內容生成英文郵件進行匯報。
這里所說的「語言完備」,指的是運用語言的能力。可以看出上面這個例子里,其實不涉及知識性的內容,因為需要它寫的內容已經提供給它了。但要寫出這封郵件,涉及到的是運用語言的能力,比如遣詞造句、語種切換、郵件格式等等。
現在我們回過頭來,嘗試分析它的這種「按照指令完成任務」的能力是怎么獲得的。在學界中,這種指令被稱為prompt,實際上對話中的用戶輸入、問答中的問題也是一種prompt,因此可以粗淺地理解為,在聊天框里輸入的所有內容都是prompt。如果了解我們在本章第一節介紹語言模型的內容,那么更嚴謹一些的說法應該是「輸入給模型的上文」都是prompt。
ChatGPT根據輸入的指令進行回復的能力,是來自于一種被稱為指令微調的模型訓練方式。其實原理很簡單,模型依然還是「根據輸入的內容,預測下一個token是什么」,只是在指令微調的階段,輸入的內容被換成了這些事先寫好的prompt,而prompt后面需要生成的內容,則是事先寫好的答案。因此在這一階段和一開始所說的無監督自回歸語言模型訓練,最大的不同在于數據。這里的數據,也就是prompt以及對應的回復,都是人寫的,換句話說,這一階段用的是人工標注的數據進行的監督訓練。
提到人工標注的數據,就自然牽涉到了所需要的數據量了,因為每一條標注數據都是需要成本的。如果是不需要標注,那么自然有海量的文本數據可供訓練,但如果要標注,那到底需要多少這種數據呢?要知道,讓標注人員手寫一個prompt,然后再手寫一個幾百字的、真實詳盡的回答,成本是很高的。根據論文《Traininglanguagemodelstofollowinstructionswithhumanfeedback》的介紹,所需要的數據其實不需要太多。雖然具體到ChatGPT到底使用了多少沒有確切的信息公開,但可以確定的是在數量級上一定遠比用來進行無監督訓練的網頁、百科和書籍所構成的數據集要小非常多。
論文地址:https://arxiv.org/pdf/2203.02155.pdf
只需要相對少量的人工標注的prompt數據就能達到讓模型按照指令做出回復的目的,這一點背后其實隱含了一個現象,在學界內被稱為prompt的泛化能力。可以想象一下,如今全世界都在不停的向ChatGPT提問,所提的問題也必定是千奇百怪的,這些問題其實就是一個個的prompt。但用來對ChatGPT進行指令微調的prompt肯定不會有這么多,這說明模型在學習到了一定量的prompt和相應的答案以后,它能夠「舉一反三」地對它沒有見過的prompt進行回答,這就是prompt的泛化能力。文章《拆解追溯GPT-3.5各項能力的起源》分析指出,這種泛化能力與在指令微調階段讓模型學習的標注數據數量以及多樣性相關。
此外,用少量的prompt數據就能微調出類似于ChatGPT這樣擁有強大能力的模型,背后還隱含了另一個猜測,即模型所表現出來的各項能力,可能在無監督訓練的階段就已經存在于模型當中了。其實這也很好理解,畢竟相比于無監督的數據,這些人工標注的prompt數量太少了,很難想象模型是通過對這些僅有的標注數據學習而產生了各種各樣的能力。從這個角度來說,指令微調的過程更多只是讓模型學會按一定的規范來進行回復,而它的知識、邏輯等能力是早已存在的。
-「客觀公正」的能力:如果對ChatGPT詢問一些有害或者有爭議的問題,可以看到ChatGPT的回答都是非常「小心」的,很像是經過訓練的新聞發言人般的回答。雖然它目前依然做得不夠好,但這種能力是OpenAI敢將它公開作為一款產品使用的核心因素。
讓模型的輸出符合人類的價值觀是OpenAI一直在做的事情。早在2020年GPT-3的時候,OpenAI就發現這種通過網上的數據訓練出來的模型,會生成帶有歧視、危險、爭議的內容。作為一個對外提供服務的產品,這些有害的內容顯然是不合適的。而現在的ChatGPT在這一點上有著明顯的改善,讓模型做出這種「行為改變」的主要方法也來自于InstructGPT的論文,更確切地說,是通過有監督的指令微調加上人類反饋的強化學習共同完成的,這一點在第二章中也已經做過介紹了。
通過上述的分析可以發現,從技術方法的角度來說,ChatGPT相關的內容都是已知的,但為什么當前只有它擁有如此驚艷的表現呢。實際上從ChatGPT推出之后,NLP社區就一直在分析這其中的原因,雖然很多結論是推測性的,但也為同類模型的國產化帶來一些啟示。
模型體量的因素
能力涌現出現的前提是模型體量達到一定的規模,雖然沒有具體的指標指引,但從目前的事實情況來看,類似于思維鏈等比較「高級」的能力,需要在數百億參數量以上的模型中才表現得足夠優異。
數據量的因素
模型的大小不是唯一的因素。DeepMind在這篇論文《TrainingCompute-OptimalLargeLanguageModels》提供了一些分析性的結論,指出訓練的數據量需要隨著模型的體量相應地增加,更確切地說,是模型訓練時「見過的token」數量,需要隨著模型體量增加。
論文地址:https://arxiv.org/pdf/2203.15556.pdf
數據質量的因素
對于無監督的數據,數據量相對而言并不是很大的障礙,但數據質量往往更加容易被忽視。實際上在GPT-3的論文中,就有專門的內容介紹數據的處理工作。為了清洗GPT-3的訓練數據,OpenAI專門訓練了一個數據過濾模型,來從海量的網頁數據中獲取更高質量的數據。相比而言,與GPT-3體量相當的一些開源模型,例如Meta的Opt和BigScience的Bloom,似乎沒有進行這一步清洗。這也許是這兩個開源模型效果劣于GPT-3的原因之一。
此外,數據質量的衡量維度不是單一的,諸如數據的多樣性、內容重復度以及數據的分布情況都是需要考慮的因素。例如雖然GPT-3所使用的網頁、百科、書籍這三大類數據中,網頁數據的總量是最多的,但在訓練時這三類數據的采樣并不是按照實際數據的多寡進行的。
另外值得一提的是,在指令微調的階段,采用人工編寫指令也許是一個重要的影響因素。InstructGPT的論文明確指出在測評過程中,采用人工編寫的指令訓練出來的模型,比采用現有的NLP數據集通過模版的方式構建指令訓練出來的模型有更好的效果。這也許解釋了在T0、FLAN等由NLP數據集構成的指令數據集訓練出來的模型為什么效果會差一些。
訓練過程的影響
這類巨型模型在訓練時通過集群進行訓練,同時采用數據并行、模型并行以及ZeRO優化器,這些方式為訓練的穩定性引入了更多的變量。如下這篇分析指出甚至模型是否采用bfloat16精度都對結果有明顯的影響。
分析鏈接:https://jingfengyang.github.io/gpt
相信了解了上面的這些內容,大家對復刻一個類ChatGPT的方式以及會面臨的問題會有一個大致的了解。有幸的是OpenAI已經證明了這技術路徑是能夠走通的,ChatGPT的出現也確實正在改變NLP技術的發展走向。
4、未來的展望
ChatGPT從2022年11月上線以來,引起了極大的關注。相信即便是非專業領域,甚至是與計算機也很少打交道的群體,或多或少地都知道它的存在,這個現象本身就已經反映出它的出現有些不同尋常。圈外的大眾更多的是以好奇、驚訝或者驚嘆的方式來感性地認識它的出現。而對從業者來說,它的出現更多的是對未來技術走向的思考。
從技術的角度來說,ChatGPT的出現標志著NLP領域的又一次范式切換。之所以說是「又」一次,是因為在2018年,也就是初代GPT發布的那一年,與之同年發布的BERT模型以自身優異的表現,開創了NLP的「預訓練+微調」范式的時代,具體內容在第二章中已經做過介紹了。這里主要介紹由ChatGPT開啟的「文本生成+指令」的范式。具體來說,就是利用訓練好的ChatGPT或類似的文本生成模型,通過輸入適當的指令來完成某一項具體的場景。
這種范式與此前的NLP技術應用有很大的不同。不論是早期的利用LDA、RNN等統計模型或很小的深度學習模型的時代,還是后來利用BERT等預訓練配合微調的時代,技術所提供的能力是相對原子化的,距離實際的應用場景有一定的距離。
就拿前面舉的讓ChatGPT根據要求寫英文郵件的例子,按照此前的做法,可能需要先抽取實體、事件等內容,然后通過模版或是模型形成郵件的樣式,再通過一個翻譯模型轉化為英文。當然如果數據量足夠訓練端到端模型的情況下,也可以跳過中間的若干步驟。但不論采用哪種方式,要么需要將最終的場景拆解成原子化的NLP任務,要么需要對應的標注數據。而對于ChatGPT來說,只需要一個合適的指令。
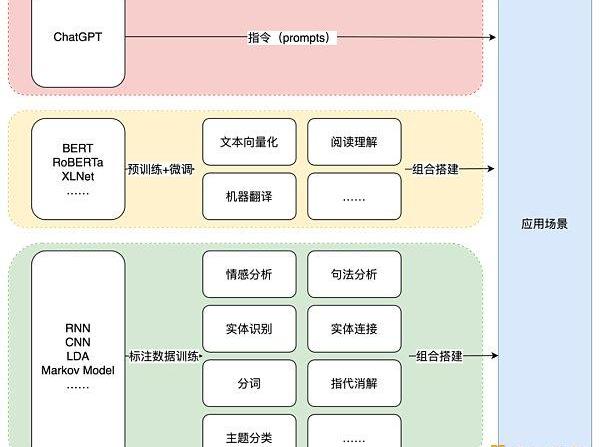
三個階段的NLP技術范式。
這種生成式模型搭配prompt的方式,直接略過了中間的各項NLP能力組件,用最直接的方式解決應用場景的問題。在這種范式下,完成終端應用的技術路徑將不再是用單點NLP能力模塊通過搭積木的方式組合起來。
當然,這個過程不是一蹴而就的,也不意味著NLP的單點能力變得不重要。從測評的角度來說,每一個單點能力的好壞依然可作為評價模型效果的指標。并且,就某些場景來說單點能力依舊是一個強需求。例如在訂票系統中本身就需要針對時間、地點進行提取。但與此前不同的是,ChatGPT本身也可以完成單點能力,而不需要使用額外的功能模塊。
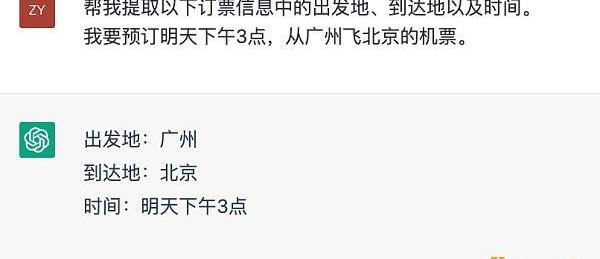
ChatGPT進行信息提取。

ChatGPT進行情感判斷。
從這個角度來說,可以把ChatGPT看作是一個以自然語言作為交互媒介的NLP工具。如果說在過去,我們是通過模型+數據+設計訓練任務的方式來完成某項NLP能力,那么ChatGPT則是通過設計指令來完成這些能力。
可想而知,ChatGPT的出現大大降低了NLP技術的應用門檻。但它目前還不是全能的。最重要的一點在于它缺乏準確可靠的垂直領域知識,為了讓它的回答可靠,最直接的方式是為它提供外部的知識來源,就像微軟將Bing的搜索結果作為它回答的信息來源那樣。
因此,「傳統」的NLP技術并不會就此完全消亡,而是會以「輔助」的角色,作為目前ChatGPT短板的補充,這也許會是未來NLP技術應用的新范式。
作者:追一科技
來源:機器之心、DeFi之道
1.穩定幣”野貓“時代:DeFi協議紛紛發行穩定幣會產生什么影響DeFi協議正在行動。隨著基于費用的商業模式的回報率下降和鏈上活動的枯竭,藍籌DeFi協議正在尋求可替代的收入來源,以強化協議并實.
1900/1/1 0:00:00金色財經報道,SuperRare創始人JonathanPerkins在NFT巴黎會議期間表示,向創作者付費的決定早在五年前就已做出.
1900/1/1 0:00:002月15日消息,美國證券交易委員會將提出一項規則,該規則將有效地要求注冊投資顧問在加密貨幣行業之外存儲數字資產.
1900/1/1 0:00:002023年世界經濟論壇年會于2023年1月16日至20日在達沃斯舉行,這是世界經濟論壇時隔三年回歸線下。與1971年達沃斯論壇第一次舉辦時相比,如今達沃斯的雪量已經減少了40%以上.
1900/1/1 0:00:00ETH鏈上數據繼續回暖 自以太坊大合并以來,ETH總量非但沒有增加,反而通過燃燒減少了23,700多枚,目前年通脹率為-0.053%.
1900/1/1 0:00:00繼去年11月裁員1.1萬人后,Meta正計劃進行新一輪裁員。從改名之時的雄心勃勃到現在的一落千丈,與CEO扎克伯格鐘情元宇宙似乎脫不了干系.
1900/1/1 0:00:00


