






 BTC/HKD-0.62%
BTC/HKD-0.62% ETH/HKD-1.02%
ETH/HKD-1.02% LTC/HKD+0.9%
LTC/HKD+0.9% DOT/HKD+3.49%
DOT/HKD+3.49% ADA/HKD+0.04%
ADA/HKD+0.04% SOL/HKD+0.38%
SOL/HKD+0.38% XRP/HKD-0.63%
XRP/HKD-0.63% DOGE/US-0.79%
DOGE/US-0.79% 
作者|劉大一恒、齊煒禎、晏宇、宮葉云、段楠、周明
編者按:微軟亞洲研究院提出新的預訓練模型ProphetNet,提出了一種新的自監督學習目標——同時預測多個未來字符,在序列到序列的多個自然語言生成任務都取得了優異性能。
大規模預訓練語言模型在自然語言理解和自然語言生成中都取得了突破性成果。這些模型通常使用特殊的自監督學習目標先在大規模無標記語料中進行預訓練,然后在下游任務上微調。
傳統自回歸語言模型通過估計文本語料概率分布被廣泛用于文本建模,序列到序列的建模,以及預訓練語言模型中。這類模型通常使用teacher-forcing的方法訓練,即每一時刻通過給定之前時刻的所有字符以預測下一個時刻的字符。然而,這種方式可能會讓模型偏向于依賴最近的字符,而非通過捕捉長依賴的信息去預測下一個字符。有如以下原因:局部的關系,如兩元字符的組合,往往比長依賴更強烈;Teacher-forcing每一時刻只考慮對下一個字符的預測,并未顯式地讓模型學習對其他未來字符的建模和規劃。最終可能導致模型對局部字符組合的學習過擬合,而對全局的一致性和長依賴欠擬合。尤其是當模型通過貪心解碼的方式生成序列時,序列往往傾向于維持局部的一致性而忽略有意義的全局結構。
0x73b地址將8052萬SAND轉入CEX:金色財經報道,據鏈上分析師余燼監測,6 小時前,0x73b 地址將 8052 萬 SAND(3244萬美元) 轉入 CEX,其中:
? 7000萬SAND轉入Binance
? 1000萬SAND轉入OKX
? 52.9萬SAND轉入Gemini
0x73b地址的SAND全部來源于The Sandbox: Genesis地址的解鎖分配,最近一次是在7天前從Genesis接收到6000萬SAND。[2023/8/11 16:19:31]
ProphetNet
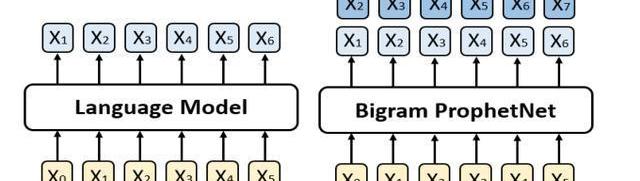
針對上述問題,我們提出了一個新的seq2seq預訓練模型,我們稱之為ProphetNet。該模型帶有一個新穎的自監督學習目標函數,即預測未來的N元組。與傳統seq2seq的Teacher-forcing每一時刻只預測下一個字符不同,ProphetNet每一時刻將學習去同時預測未來的N個字符。如圖1所示:
Opside已上線Pre-alpha激勵測試網,預計將運行大約三個月:5月24日消息,去中心化ZK Raas平臺Opside宣布,已上線Pre-alpha激勵測試網,預計將運行大約三個月,鼓勵PoS驗證者、PoW礦工、開發人員和所有最終用戶的廣泛參與。Opside旨在通過該測試網測試和完善以下功能:1.混合PoS和PoW共識機制的集成與有效性;2.成功適應并與ETH2.0共識模型保持一致;3.ZK-Rollup執行環境的操作性能和靈活性;4.實施各種策略,以實現不同層和ZK-Rollups之間順利和安全的資產轉移;5.代幣經濟學模型的實際應用。[2023/5/24 15:22:33]
圖1:左邊是傳統的語言模型,每一時刻預測下一時刻的字符。右邊是Bigram形式下的ProphetNet,每一時刻同時預測未來的兩個字符。
預測未來N元組這一自監督學習目標在訓練過程中顯式地鼓勵模型在預測下一個字符時考慮未來更遠的字符,做到對未來字符的規劃,以防止模型對強局部相關過擬合。
ProphetNet基于Transformer的seq2seq架構,其設計有兩個目標:1.模型能夠以高效的方式在訓練過程中完成每時刻同時預測未來的N個字符;2.模型可以靈活地轉換為傳統的seq2seq架構,以在推理或微調階段兼容現有的方法和任務。為此,我們受XLNet中Two-streamselfattention的啟發,提出了用于模型decoder端的N-streamself-attention機制。圖2展示了bigram形式下的N-streamself-attention樣例。
汽車品牌日產申請4個新的Web3商標,并在元宇宙中試銷:3月13日消息,日本汽車品牌日產近日在美國提交了四個與Web3相關的新商標,而其日本子公司正在元宇宙中試驗汽車銷售。
根據日產3月7日向美國專利商標局(USPTO)提交的商標申請,新申請涵蓋了其英菲尼迪(INFINITI)、Nismo和日產品牌,范圍涵蓋虛擬服+汽車、虛擬商品商店+NFT、NFT市場+交易+鑄造、元宇宙廣告服務等。
上周,3月8日,日產日本公司宣布將對其虛擬商店“日產Hype實驗室”進行為期三個月的“示范實驗”,以在元宇宙中“研究、咨詢、試駕和購買日產汽車”。 該實驗將于6月30日截止。顧客可以通過個人電腦或智能手機“一天24小時”訪問虛擬店面。客戶可以創建自己定制的虛擬形象,在特定的時間內,甚至可以與虛擬銷售人員互動。根據公告,客戶可以通過虛擬銷售辦公室訂購汽車并敲定購買合同。(Cointelegraph)[2023/3/13 13:00:14]
除了原始的multi-headself-attention之外,N-streamself-attention包含了額外的N個predictingstreamself-attention,用于分別預測第n個未來時刻的字符所示。每一個predictingstream與mainstream共享參數,我們可以隨時關閉predictingstream以讓模型轉換回傳統seq2seq的模式。
以太坊L2網絡總鎖倉量為42.1億美元:金色財經報道,L2BEAT數據顯示,截至12月26日,以太坊Layer2上總鎖倉量為42.1億美元。其中鎖倉量最高的為擴容方案Arbitrum,約22.9億美元,占比54.28%;其次是Optimism,鎖倉量為11.2億美元,占比26.79%;第三為dYdX,鎖倉量為3.92億美元,占比9.27%[2022/12/26 22:07:35]
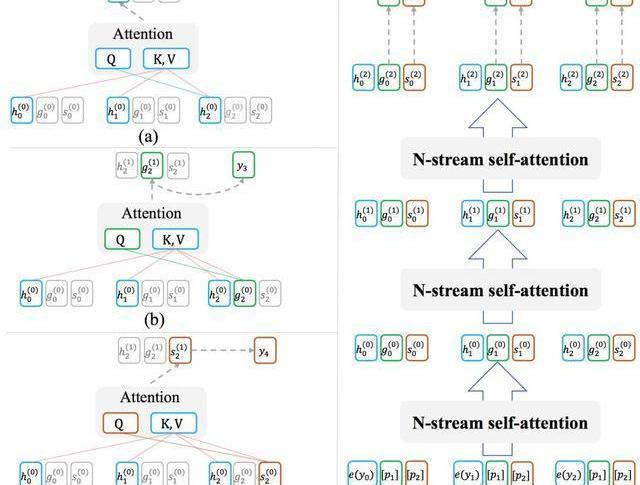
圖2:(a)為mainstreamself-attention;(b)為1-stpredictingstreamself-attention;(c)為2-ndpredictingstreamself-attention;(d)展示了n-streamself-attention的輸入輸出及流程。
由于難以獲取到大量帶標記的序列對數據,我們用去噪的自編碼任務通過大量無標記文本預訓練ProphetNet。去噪的自編碼任務旨在輸入被噪音函數破壞后的序列,讓模型學習去復原原始序列。該任務被廣泛應于seq2seq模型的預訓練中,如MASS、BART、T5等。本文中使用MASS的預訓練方式,通過引入提出的predictingn-stream自監督學習目標函數預訓練ProphetNet。我們以bigram形式的ProphetNet為例,整個流程如圖3所示:
Aztec Network:注意到FTX告知用戶不要與Aztec進行交互的報道,將進一步降低風險:8月20日消息,基于ZKRollup的隱私和擴容解決方案Aztec Network在Twitter上表稱注意到了FTX告知用戶不要與Aztec進行交互的報道,并表示其認為隱私本身合法的,但同時也在進行一些降低風險的努力,包括將每筆交易金額限制為5枚以太坊或1萬枚DAI。此外,未來Aztec還將設置包括每日存款上限、特定IP的存款限制在內的措施來提高安全性。[2022/8/20 12:37:30]
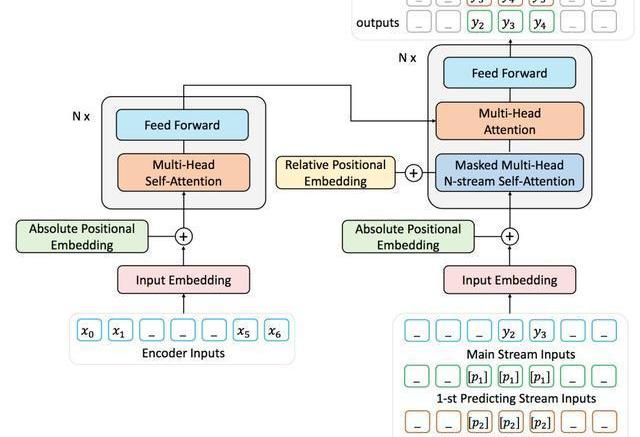
圖3:二元形式下的Prophet整體框架圖
實驗結果
我們使用兩個規模的語料數據訓練ProphetNet。ProphetNet包含12層的encoder和12層的decoder,隱層大小為1024。先在BERT所使用的BookCorpus+Wikipedia的數據上預訓練模型,將模型在Textsummarization和Questiongeneration兩個NLG任務上的三個數據集微調并評估模型性能。與使用同等規模數據的預訓練模型相比,ProphetNet在CNN/DailyMail、Gigaword和SQuAD1.1questiongeneration數據集上都取得了最高的性能,如表1-3所示。
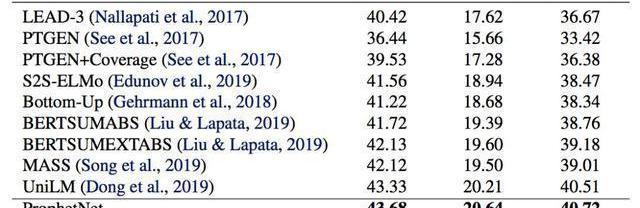
表1:CNN/DailyMail測試集結果
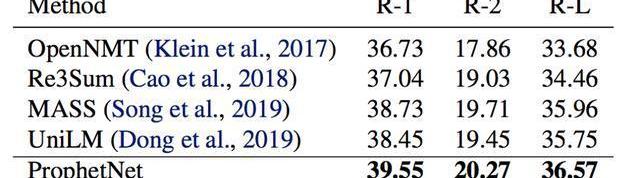
表2:Gigaword測試集結果
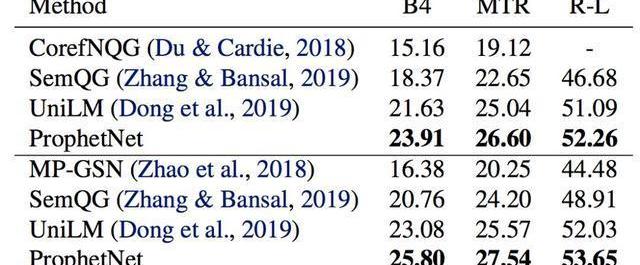
表3:SQuAD1.1測試集結果SQuAD1.1交換驗證測試集結果
除了使用16GB的語料訓練模型,我們也進行了更大規模的預訓練實驗。該實驗中,我們使用了160GB的語料預訓練ProphetNet。我們展示了預訓練14個epoch后的ProphetNet在CNN/DailyMail和Gigaword兩個任務上微調和測試的結果。如表4所示。需要注意的是,在相同大小的訓練數據下,我們模型的預訓練epoch僅約為BART的三分之一。我們模型的訓練數據使用量僅約為T5和PEGASUSLARGE的五分之一,約為PEGASUSLARGE的二十分之一。盡管如此,我們的模型仍然在CNN/DailyMail上取得了最高的ROUGE-1和ROUGE-LF1scores。并在Gigaword上實現了新的state-of-the-art性能。

表4:模型經大規模語料預訓練后在CNN/DailyMail和Gigaword測試集的結果
為了進一步探索ProphetNet的性能,我們在不預訓練的情況下比較了ProphetNet和Transformer在CNN/DailyMail上的性能。實驗結果如表5所示,ProphetNet在該任務上超越了同等參數量的Transformer。
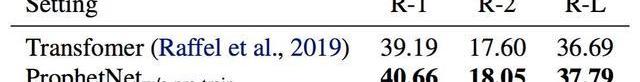
表5:模型不經過預訓練在CNN/DailyMail驗證集結果
總結
本文介紹了微軟亞洲研究院在序列到序列模型預訓練的一個工作:ProphetNet,該模型提出了一種新的自監督學習目標,在同一時刻同時預測多個未來字符。并通過提出的N-streamself-attention機制高效地實現了模型在該目標下的訓練。實驗表明,該模型在序列到序列的多個自然語言生成任務都取得了不錯的性能。我們將在之后嘗試使用更大規模的模型架構和語料進行預訓練,并進一步深入地探索該機制。
論文鏈接:https://arxiv.org/pdf/2001.04063.pdf
原力計劃
《原力計劃-學習力挑戰》正式開始!即日起至3月21日,千萬流量支持原創作者!更有專屬等你來挑戰
Python數據清理終極指南口罩檢測識別率驚人,這個Python項目開源了談論新型冠狀病、比特幣、蘋果公司……沃倫巴菲特受訪中的18個金句,值得一看!天貓超市回應大數據殺熟;華為MateXs被熱炒至6萬元;Elasticsearch7.6.1發布一張圖對比阿里、騰訊復工的區別不看就虧系列!這里有完整的Hadoop集群搭建教程,和最易懂的Hadoop概念!|附代碼
大家好,我是cf的菜雞up主至糖至健,兒童節在6.1到來,也代表著掌火六月積分兌換的更新打開掌火,在推薦專區找到“積分兌換”字樣的按鈕,點擊即可參與積分兌換版塊的專屬內容.
1900/1/1 0:00:00在影視劇中,我們經常聽到銀子這個“名詞”。眾所周知,銀子是我國古代社會中貨幣的一種,尤其是唐宋以后得朝代,銀子的使用非常廣泛。然而,銀子作為我國古代貨幣的一種,它有著無法替代的重要作用.
1900/1/1 0:00:00東方網·縱相新聞記者馮茵倫陳思眾 最新 朝中社9日報道,朝鮮方面宣布“切斷”與韓國的所有聯系渠道.
1900/1/1 0:00:00據說,古往今來最暢銷的詩人乃莎士比亞,排名第二的是老子,第三名則非紀伯倫莫屬。哈利勒·紀伯倫是黎巴嫩著名詩人和作家,以獨樹一幟的藝術風格彪炳東方文學史冊.
1900/1/1 0:00:00人在幣圈,遵從本心、順其自然地“鏈賺”。我有“4PAI”計劃:實在參與的“行動派”系列、興致研討的“隨心Pie”系列、全球引智的“薏米Pie”系列、學習進階的“學緣Pie”系列.
1900/1/1 0:00:00第十二屆陸家嘴論壇 在6月18日舉行的第十二屆陸家嘴論壇上,中共中央局委員、國務院副總理劉鶴指出,堅持“建制度、不干預、零容忍”,加快發展資本市場.
1900/1/1 0:00:00


