






 BTC/HKD+0.95%
BTC/HKD+0.95% ETH/HKD+3%
ETH/HKD+3% LTC/HKD+2.71%
LTC/HKD+2.71% DOT/HKD+5.02%
DOT/HKD+5.02% ADA/HKD+3.07%
ADA/HKD+3.07% SOL/HKD+1.15%
SOL/HKD+1.15% XRP/HKD+0.32%
XRP/HKD+0.32% DOGE/US+2.15%
DOGE/US+2.15%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
Chainalysis CEO:以太坊正在促進其他加密資產的增長:金色財經報道,Chainalysis CEO Michael Gronager在接受采訪時表示,以太坊的根本性變化正在促進其他加密資產的增長,尤其是在一個子行業。?我們看到以太坊在過去幾周里增長了很多,然后大約一個月前,我們看到了以太坊的平臺變化。網絡在各種方面變得穩定并且變得更好。所以我認為這促進了投資者對整個以太坊的更多信任。另外,區塊鏈數據平臺負責人認為,以太坊(ETH)在過去幾周的價格大幅上漲,主要是由于協議的變化和網絡的增長,以及去中心化金融(DeFi)。(dailyhodl)[2021/9/4 23:00:34]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
Cardano創始人Charles Hoskinson重回ETC Cooperative董事會:ETC Cooperative近日發推宣布Cardano創始人及IOHK首席執行官Charles Hoskinson重新成為其董事會新成員,并表示其一直是ETC的支持者,在該項目上有著獨特的遠見和經驗。
據悉,早在2018年初,Charles就曾是ETC Cooperative最初顧問委員會的成員。現有六名董事會成員為Barry Silbert、Cody Burns、Elaine Ou、Roy Zou、Charles Hoskinson和Craig Salm。[2021/7/10 0:41:44]
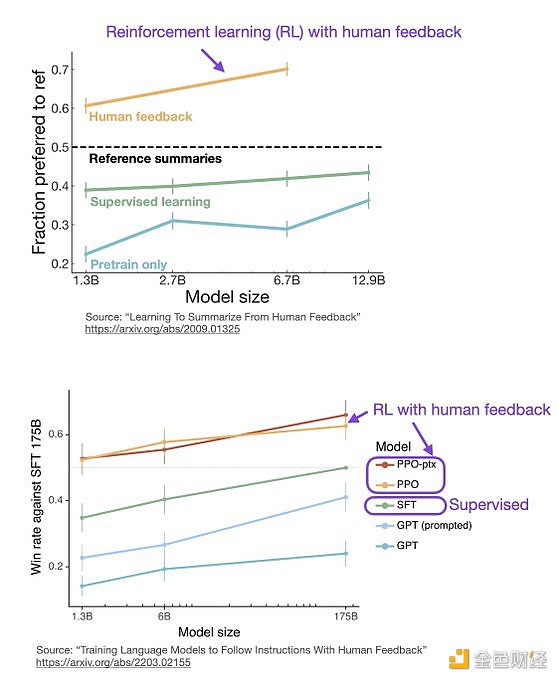
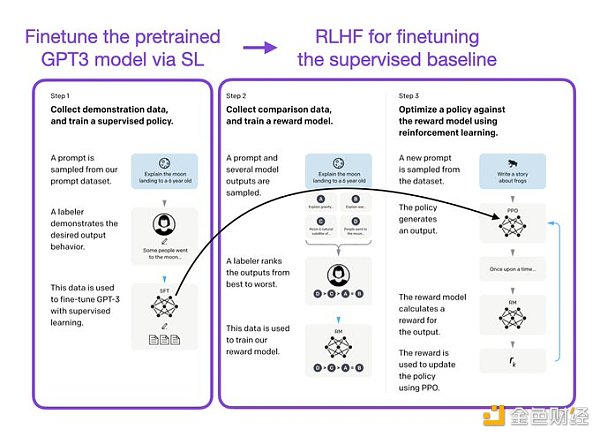
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
Chainalysis計劃幫助美國政府出售已沒收比特幣:Chainalysis計劃協助美國政府出售已沒收比特幣,價值或達數百萬美元。本周四(11月12日),Chainalysis宣布與資產咨詢公司AssetReality合作推出一項用于存儲和出售美國政府沒收比特幣程序。就在上周,美國司法部宣布查獲暗網絲路擁有的價值10億美元比特幣,有消息稱該機構預計會定期拍賣已沒收的比特幣,而通過拍賣方式銷售比特幣有可能為美國政府帶來數千萬美元收入。截至本文撰寫時,Chainalysis尚未就此事做出官方回應。(Coindesk)[2020/11/12 14:09:01]
動態 | 區塊鏈分析公司Chainalysis裁員20%:金色財經報道,本周四,Chainalysis解雇了39名員工,約占其員工總數的20%。Chainalysis傳播總監Maddie Kennedy表示,此次裁員分布于幾乎全部職位,研發團隊的削減幅度最大。Kennedy表示,裁員有助于使已有5年歷史的Chainalysis走上“盈利之路”,從而使該公司能夠將資源轉移到產品團隊和市場戰略中。[2019/11/22]
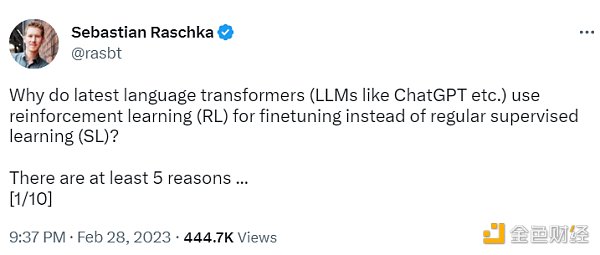
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
Tags:CHAAINChainHAIeubchainblockchain錢包appBlockgameChainVince Chain
華盛頓特區 2023 年 3 月 2 日早上好。我很高興加入投資者咨詢委員會。按照慣例,我想指出我的觀點是我自己的,我不代表委員會或 SEC 工作人員發言.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:518.55億美元 DeFi總市值及前十代幣 數據來源:coingecko2、過去24小時去中心化交易所的交易量26.
1900/1/1 0:00:00DeFi數據 1、DeFi代幣總市值:480.08億美元 DeFi總市值及前十代幣 數據來源:coingecko2、過去24小時去中心化交易所的交易量23.
1900/1/1 0:00:00▌國內外科技公司集體“壓減”元宇宙3月4日消息,隨著AIGC(利用人工智能技術生成內容)熱浪持續席卷,科技行業此前集體熱衷的元宇宙熱度下降.
1900/1/1 0:00:00撰文:Louis Cooper編譯:0x11,Foresight News上海升級將釋放價值超過 270 億美元的 ETH,這意味著 LSD 市場的爭奪戰已經開始.
1900/1/1 0:00:002018 年 7 月,萬向集團董事長肖風博士在一次演講中提到:“區塊鏈行業有可能出現 5 萬億級別的公司”.
1900/1/1 0:00:00


